
MATLAB快速入门(五)
一.简介
本篇参考官方入门文档编写
前提准备:
- MATLAB
二. 快速入门(五)(线性代数)
1. MATLAB 环境中的矩阵
本主题介绍如何在 MATLAB® 中创建矩阵和执行基本矩阵计算。
MATLAB 环境使用矩阵来表示包含以二维网格排列的实数或复数的变量。更广泛而言,数组为向量、矩阵或更高维度的数值网格。MATLAB 中的所有数组都是矩形,在这种意义上沿任何维度的分量向量的长度均相同。矩阵中定义的数学运算是线性代数的主题。
创建矩阵
MATLAB 提供了许多函数,用于创建各种类型的矩阵。例如,您可以使用基于帕斯卡三角形的项创建一个对称矩阵:
1 | A = pascal(3) |
您也可以创建一个非对称幻方矩阵,它的行总和与列总和相等:
1 | B = magic(3) |
另一个示例是由随机整数构成的 3×2 矩形矩阵:在这种情况下,randi 的第一个输入描述整数可能值的范围,后面两个输入描述行和列的数量。
1 | C = randi(10,3,2) |
列向量为 m×1 矩阵,行向量为 1×n 矩阵,标量为 1×1 矩阵。要手动定义矩阵,请使用方括号 [ ] 来表示数组的开始和结束。在括号内,使用分号 ; 表示行的结尾。在标量(1×1 矩阵)的情况下,括号不是必需的。例如,以下语句生成一个列向量、一个行向量和一个标量:
1 | u = [3; 1; 4] |
有关创建和处理矩阵的详细信息,请参阅创建、串联和扩展矩阵。
矩阵的加法和减法
矩阵和数组的加减法是逐个元素执行的,或者说是按元素执行的。例如,A 加 B 之后再减去 A 又可以得到 B:
1 | X = A + B |
加法和减法要求两个矩阵具有兼容的维度。如果维度不兼容,将会导致错误:
1 | X = A + C |
有关详细信息,请参阅数组与矩阵运算。
向量乘积和转置
长度相同的行向量和列向量可以按任一顺序相乘。其结果是一个标量(称为内积)或一个矩阵(称为外积):
1 | u = [3; 1; 4]; |
对于实矩阵,转置运算对 aij 和 aji 进行交换。对于复矩阵,还要考虑是否用数组中复数项的复共轭来形成复共轭转置。MATLAB 使用撇号运算符 (') 执行复共轭转置,使用点撇号运算符 (.') 执行无共轭的转置。对于包含所有实数元素的矩阵,这两个运算符返回相同结果。
示例矩阵 A = pascal(3) 是对称的,因此 A' 等于 A。然而,B = magic(3) 不是对称的,因此 B' 的元素是 B 的元素沿主对角线反转之后的结果:
1 | B = magic(3) |
对于向量,转置会将行向量变为列向量(反之亦然):
1 | x = v' |
如果 x 和 y 均为实数列向量,则乘积 x*y 不确定,但以下两个乘积
1 | x'*y |
和
1 | y'*x |
产生相同的标量结果。此参数使用很频繁,它有三个不同的名称内积、标量积或点积。甚至还有一个专门的点积函数,称为 dot。
对于复数向量或矩阵 z,参量 z' 不仅可转置该向量或矩阵,而且可将每个复数元素转换为其复共轭数。也就是说,每个复数元素的虚部的正负号将会发生更改。以如下复矩阵为例:
1 | z = [1+2i 7-3i 3+4i; 6-2i 9i 4+7i] |
z 的复共轭转置为:
1 | z' |
非共轭复数转置(其中每个元素的复数部分保留其符号)表示为 z.':
1 | z.' |
对于复数向量,两个标量积 x'*y 和 y'*x 互为复共轭数,而复数向量与其自身的标量积 x'*x 为实数。
矩阵乘法
矩阵乘法是以这样一种方式定义的:反映底层线性变换的构成,并允许紧凑表示联立线性方程组。如果 A 的列维度等于 B 的行维度,或者其中一个矩阵为标量,则可定义矩阵乘积 C = AB。如果 A 为 m×p 且 B 为 p×n,则二者的乘积 C 为 m×n。该乘积实际上可以使用 MATLAB for 循环、colon 表示法和向量点积进行定义:
1 | A = pascal(3); |
MATLAB 使用星号表示矩阵乘法,如 C = A*B 中所示。矩阵乘法不适用交换律;即 A*B 通常不等于 B*A:
1 | X = A*B |
矩阵可以在右侧乘以列向量,在左侧乘以行向量:
1 | u = [3; 1; 4]; |
矩形矩阵乘法必须满足维度兼容性条件:由于 A 是 3×3 矩阵,C 是 3×2 矩阵,因此可将二者相乘得到 3×2 结果(共同的内部维度会消去):
1 | X = A*C |
但是,乘法不能以相反的顺序执行:
1 | Y = C*A |
您可以将任何内容与标量相乘:
1 | s = 10; |
当您将数组与标量相乘时,标量将隐式扩展为与另一输入相同的大小。这通常称为标量扩展。
单位矩阵
普遍接受的数学表示法使用大写字母 I 来表示单位矩阵,即主对角线元素为 1 且其他位置元素为 0 的各种大小的矩阵。这些矩阵具有以下属性:无论维度是否兼容,AI = A 和 IA = A。
原始版本的 MATLAB 不能将 I 用于此用途,因为它不会区分大小字母和小写字母,并且 i 已用作下标和复数单位。因此,引入了英语双关语。函数
1 | eye(m,n) |
返回 m×n 矩形单位矩阵,eye(n) 返回 n×n 单位方阵。
矩阵求逆
如果矩阵 A 为非奇异方阵(非零行列式),则方程 AX = I 和 XA = I 具有相同的解 X。此解称为 A 的逆矩阵,表示为 A-1。inv 函数和表达式 A^-1 均可对矩阵求逆。
1 | A = pascal(3) |
通过 det 计算的行列式表示由矩阵描述的线性变换的缩放因子。当行列式正好为零时,矩阵为奇异矩阵,因此不存在逆矩阵。
1 | d = det(A) |
有些矩阵接近奇异矩阵,虽然存在逆矩阵,但计算容易出现数值误差。cond 函数计算逆运算的条件数,它指示矩阵求逆结果的精度。条件数的范围是从 1(数值稳定的矩阵)到 Inf(奇异矩阵)。
1 | c = cond(A) |
很少需要为某个矩阵构造显式逆矩阵。当解算线性方程组 Ax = b 时,往往会错误使用 inv。从执行时间和数值精度方面而言,求解此方程的最佳方法是使用矩阵反斜杠运算符,即 x = A\b。有关详细信息,请参阅 mldivide。
Kronecker 张量积
两个矩阵的 Kronecker 乘积 kron(X,Y) 为 X 的元素与 Y 的元素的所有可能乘积构成的较大矩阵。如果 X 为 m×n 且 Y 为 p×q,则 kron(X,Y) 为 mp×nq。元素以特定方式排列,呈现 X 的每个元素分别与整个矩阵 Y 相乘的结果。
1 | [X(1,1)*Y X(1,2)*Y . . . X(1,n)*Y |
Kronecker 乘积通常与元素为 0 和 1 的矩阵配合使用,以构建小型矩阵的重复副本。例如,如果 X 为 2×2 矩阵
1 | X = [1 2 |
且 I = eye(2,2) 为 2×2 单位矩阵,则:
1 | kron(X,I) |
并且
1 | kron(I,X) |
除了 kron 之外,对复制数组有用的其他函数还有 repmat、repelem 和 blkdiag。
向量范数和矩阵范数
向量 x 的 p-范数,
‖x‖p=(∑∣∣x**i∣∣p)1/p ,
使用 norm(x,p) 进行计算。此运算是为 p > 1 的任意值定义的,但最常见的 p 值为 1、2 和 ∞。默认值为 p = 2,这与欧几里德长度或向量幅值对应:
1 | v = [2 0 -1]; |
矩阵 A 的 p-范数,
‖A‖p=maxx‖A**x‖p‖x‖p,
可以针对 p = 1、2 和 ∞ 通过 norm(A,p) 进行计算。同样,默认值也为 p = 2:
1 | A = pascal(3); |
如果要计算矩阵的每行或每列的范数,可以使用 vecnorm:
1 | vecnorm(A) |
使用线性代数方程函数的多线程计算
对于许多线性代数函数和按元素的数值函数,MATLAB 软件支持多线程计算。这些函数将自动在多个线程上执行。要使函数或表达式在多个 CPU 上更快地执行,必须满足许多条件:
- 函数执行的运算可轻松划分为并发执行的多个部分。这些部分必须能够在进程之间几乎不通信的情况下执行。它们应需要很少的序列运算。
- 数据大小足以使并发执行的任何优势在重要性方面超过对数据分区和管理各个执行线程所需的时间。例如,仅当数组包含数千个或以上的元素时,大多数函数才会加速。
- 运算未与内存绑定;处理时间不受内存访问时间控制。一般而言,复杂函数比简单函数速度更快。
对于大型双精度数组(约 10,000 个元素),矩阵乘法 (X*Y) 和矩阵乘幂 (X^p) 运算符会大幅增加速度。矩阵分析函数 det、rcond、hess 和 expm 也会对大型双精度数组大幅增加速度。
相关主题
2. 线性方程组
计算注意事项
进行科学计算时,最重要的一个问题是对联立线性方程组求解。
在矩阵表示法中,常见问题采用以下形式:给定两个矩阵 A 和 b,是否存在一个唯一矩阵 x 使 Ax = b 或 xA = b?
考虑 1×1 示例具有指导意义。例如,方程
7x = 21
是否具有唯一解?
答案当然是肯定的。方程有唯一解 x = 3。通过除法很容易求得该解:
x = 21/7 = 3。
该解通常不是通过计算 7 的倒数求得的,即先计算 7–1 = 0.142857…,然后将 7–1 乘以 21。这将需要更多的工作,而且如果 7–1 以有限位数表示时,准确性会较低。类似注意事项也适用于多个未知数的线性方程组;MATLAB 在解此类方程时不会计算矩阵的逆。
尽管这不是标准的数学表示法,但 MATLAB 使用标量示例中常见的除法术语来描述常规联立方程组的解。斜杠 / 和反斜杠 \ 这两个除号分别对应 MATLAB 函数 mrdivide 和 mldivide。两种运算符分别用于未知矩阵出现在系数矩阵左侧或右侧的情况:
x = b/A |
表示使用 mrdivide 获得的矩阵方程 xA = b 的解。 |
|---|---|
x = A\b |
表示使用 mldivide 获得的矩阵方程 Ax = b 的解。 |
考虑将方程 Ax = b 或 xA = b 的两端“除以”A。系数矩阵 A 始终位于“分母”中。
x = A\b 的维度兼容性条件要求两个矩阵 A 和 b 的行数相同。这样,解 x 的列数便与 b 的列数相同,并且其行维度等于 A 的列维度。对于 x = b/A,行和列的角色将会互换。
实际上,Ax=b 形式的线性方程组比 xA=b 形式的线性方程组更常见。因此,反斜杠的使用频率要远高于斜杠的使用频率。本节其余部分将重点介绍反斜杠运算符;斜杠运算符的对应属性可以从以下恒等式推知:
1 | (b/A)' = (A'\b'). |
系数矩阵 A 不需要是方阵。如果 A 的大小为 m×n,则有三种情况:
| m = n | 方阵方程组。求精确解。 |
|---|---|
| m > n | 超定方程组,即方程个数多于未知数个数。求最小二乘解。 |
| m < n | 欠定方程组,即方程个数少于未知数个数。使用最多 m 个非零分量求基本解。 |
mldivide 算法. mldivide 运算符使用不同的求解器来处理不同类型的系数矩阵。通过检查系数矩阵自动诊断各种情况。有关详细信息,请参阅 mldivide 参考页的“算法”小节。
通解
线性方程组 Ax = b 的通解描述了所有可能的解。可以通过以下方法求通解:
- 求对应的齐次方程组 Ax = 0 的解。使用
null命令通过键入null(A)来执行此操作。这会将解空间的基向量恢复为 Ax = 0。任何解都是基向量的线性组合。 - 求非齐次方程组 Ax = b 的特定解。
然后,可将 Ax = b 的任何解写成第 2 步中的 Ax = b 的特定解加上第 1 步中的基向量的线性组合之和。
本节其余部分将介绍如何使用 MATLAB 求 Ax = b 的特定解,如第 2 步中所述。
方阵方程组
最常见的情况涉及到一个方阵系数矩阵 A 和一个右侧单列向量 b。
非奇异系数矩阵. 如果矩阵 A 是非奇异矩阵,则解 x = A\b 的大小与 b 的大小相同。例如:
1 | A = pascal(3); |
可以确认 A*x 恰好等于 u。
如果 A 和 b 为方阵并且大小相同,则 x= A\b 也具有相同大小:
1 | b = magic(3); |
可以确认 A*x 恰好等于 b。
以上两个示例具有确切的整数解。这是因为系数矩阵选为 pascal(3),这是满秩矩阵(非奇异的)。
奇异系数矩阵. 如果方阵 A 不包含线性无关的列,则该矩阵为奇异矩阵。如果 A 为奇异矩阵,则 Ax = b 的解将不存在或不唯一。如果 A 接近奇异或检测到完全奇异性,则反斜杠运算符 A\b 会发出警告。
如果 A 为奇异矩阵并且 Ax = b 具有解,可以通过键入以下内容求不是唯一的特定解
1 | P = pinv(A)*b |
pinv(A) 是 A 的伪逆。如果 Ax = b 没有精确解,则 pinv(A) 将返回最小二乘解。
例如:
1 | A = [ 1 3 7 |
为奇异矩阵,可以通过键入以下内容进行验证:
1 | rank(A) |
由于 A 不是满秩,它有一些等于零的奇异值。
精确解。对于 b =[5;2;12],方程 Ax = b 具有精确解,给定
1 | pinv(A)*b |
通过键入以下内容验证 pinv(A)*b 是否为精确解
1 | A*pinv(A)*b |
最小二乘解。但是,如果 b = [3;6;0],则 Ax = b 没有精确解。在这种情况下,pinv(A)*b 会返回最小二乘解。键入
1 | A*pinv(A)*b |
则不会返回原始向量 b。
通过得到增广矩阵 [A b] 的简化行阶梯形式,可以确定 Ax = b 是否具有精确解。为此,对于此示例请输入
1 | rref([A b]) |
由于最下面一行全部为零(最后一项除外),因此该方程无解。在这种情况下,pinv(A) 会返回最小二乘解。
超定方程组
尝试此示例Copy Command Copy Code
此示例说明在对试验数据的各种曲线拟合中通常会如何遇到超定方程组。
在多个不同的时间值 t 对数量 y 进行测量以生成以下观测值。可以使用以下语句输入数据并在表中查看该数据。
1 | t = [0 .3 .8 1.1 1.6 2.3]'; |
尝试使用指数衰减函数对数据进行建模
y(t)=c1+c2e−t。
上一方程表明,向量 y 应由两个其他向量的线性组合来逼近。一个是元素全部为 1 的常向量,另一个是带有分量 exp(-t) 的向量。未知系数 c1 和 c2 可以通过执行最小二乘拟合来计算,这样会最大限度地减小数据与模型偏差的平方和。在两个未知系数的情况下有六个方程,用 6×2 矩阵表示。
1 | E = [ones(size(t)) exp(-t)] |
使用反斜杠运算符获取最小二乘解。
1 | c = E\y |
也就是说,对数据的最小二乘拟合为
y(t)=0.4760+0.3413e−t.
以下语句按固定间隔的 t 增量为模型求值,然后与原始数据一同绘制结果:
1 | T = (0:0.1:2.5)'; |
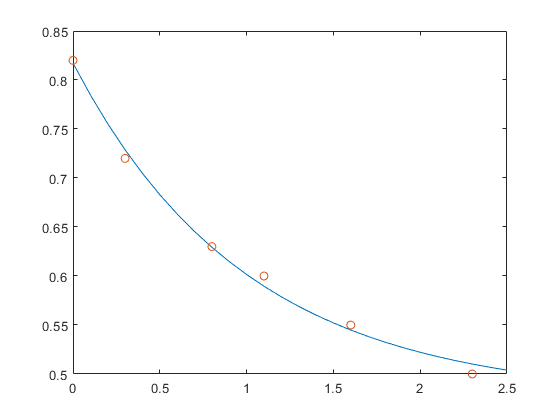
E*c 与 y 不完全相等,但差值可能远小于原始数据中的测量误差。
如果矩形矩阵 A 没有线性无关的列,则该矩阵秩亏。如果 A 秩亏,则 AX = B 的最小二乘解不唯一。如果 A 秩亏,则 A\B 会发出警告,并生成一个最小二乘解。您可以使用 lsqminnorm 求在所有解中具有最小范数的解 X。
欠定方程组
本例演示了欠定方程组的解不唯一的情况。欠定线性方程组包含的未知数比方程多。MATLAB 矩阵左除运算求基本最小二乘解,对于 m×n 系数矩阵,它最多有 m 个非零分量。
以下是一个简单的随机示例:
1 | R = [6 8 7 3; 3 5 4 1] |
线性方程组 Rp = b 有两个方程,四个未知数。由于系数矩阵包含较小的整数,因此适合使用 format 命令以有理格式显示解。通过以下命令可获取特定解
1 | format rat |
其中一个非零分量为 p(2),因为 R(:,2) 是具有最大范数的 R 的列。另一个非零分量为 p(4),因为 R(:,4) 在消除 R(:,2) 后起控制作用。
欠定方程组的完全通解可以通过 p 加上任意零空间向量线性组合来表示,可以使用 null 函数(使用请求有理基的选项)计算该空间向量。
1 | Z = null(R,'r') |
可以确认 R*Z 为零,并且残差 R*x - b 远远小于任一向量 x(其中
1 | x = p + Z*q |
由于 Z 的列是零空间向量,因此 Z*q 是以下向量的线性组合:
Z**q=(⇀x1⇀x2)(u**w)=u⇀x1+w⇀x2 .
为了说明这一点,选择任意 q 并构造 x。
1 | q = [-2; 1]; |
计算残差的范数。
1 | format short |
如果有无限多个解,则最小范数解具有特别意义。您可以使用 lsqminnorm 计算最小范数最小二乘解。该解具有 norm(p) 的最小可能值。
1 | p = lsqminnorm(R,b) |
多右端线性方程组的求解
某些问题涉及求解具有相同系数矩阵 A 但具有不同右端 b 的线性方程组。如果可以同时使用不同的 b 值,则可以将 b 构造为多列矩阵,并使用单个反斜杠命令求解所有方程组:X = A\[b1 b2 b3 …]。
但是,有时不同的 b 值并非全部同时可用,也就是说,您需要连续求解若干方程组。如果使用斜杠 (/) 或反斜杠 () 求解其中一个方程组,则该运算符会对系数矩阵 A 进行分解,并使用此矩阵分解来求解。然而,随后每次使用不同的 b 求解类似方程组时,运算符都会对 A 进行同样的分解,而这是一次冗余计算。
此问题的求解是预先计算 A 的分解,然后重新使用因子对 b 的不同值求解。但是,实际上,以这种方式预先计算分解可能很困难,因为需要知道要计算的分解(LU、LDL、Cholesky 等)以及如何乘以因子才能对问题求解。例如,使用 LU 分解,您需要求解两个线性方程组才能求解原始方程组 Ax = b:
1 | [L,U] = lu(A); |
对于具有若干连续右端的线性方程组,建议使用 decomposition 对象求解。借助这些对象,您可利用预先计算矩阵分解带来的性能优势,而不必了解如何使用矩阵因子。您可以将先前的 LU 分解替换为:
1 | dA = decomposition(A,'lu'); |
如果您不确定要使用哪种分解,decomposition(A) 会根据 A 的属性选择正确的类型,类似于反斜杠的功能。
以下简单测试验证了此方法可能带来的性能优势。该测试分别使用反斜杠 () 和 decomposition 对同一稀疏线性方程组求解 100 次。
1 | n = 1e3; |
对于这个问题,decomposition 求解比单独使用反斜杠要快得多,而语法仍然很简单。
迭代法
如果系数矩阵 A 很大并且是稀疏矩阵,分解方法一般情况下将不会有效。迭代方法可生成一系列近似解。MATLAB 提供了多个迭代方法来处理大型的稀疏输入矩阵。
| 函数 | 说明 |
|---|---|
pcg |
预条件共轭梯度法。此方法适用于 Hermitian 正定系数矩阵 A。 |
bicg |
双共轭梯度法 |
bicgstab |
双共轭梯度稳定法 |
bicgstabl |
双共轭梯度稳定法(l) |
cgs |
共轭梯度二乘法 |
gmres |
广义最小残差法 |
lsqr |
LSQR 方法 |
minres |
最小残差法。此方法适用于 Hermitian 系数矩阵 A。 |
qmr |
拟最小残差法 |
symmlq |
对称的 LQ 方法 |
tfqmr |
无转置 QMR 方法 |
多线程计算
对于许多线性代数函数和按元素的数值函数,MATLAB 软件支持多线程计算。这些函数将自动在多个线程上执行。要使函数或表达式在多个 CPU 上更快地执行,必须满足许多条件:
- 函数执行的运算可轻松划分为并发执行的多个部分。这些部分必须能够在进程之间几乎不通信的情况下执行。它们应需要很少的序列运算。
- 数据大小足以使并发执行的任何优势在重要性方面超过对数据分区和管理各个执行线程所需的时间。例如,仅当数组包含数千个或以上的元素时,大多数函数才会加速。
- 运算未与内存绑定;处理时间不受内存访问时间控制。一般而言,复杂函数比简单函数速度更快。
如果启用多线程,inv、lscov、linsolve 和 mldivide 将会对大型双精度数组(约 10,000 个元素或更多)大幅增加速度。
另请参阅
mldivide | mrdivide | pinv | decomposition | lsqminnorm
相关主题
3. 分解
简介
本节中讨论的所有三种矩阵分解利用了三角形矩阵,其中对角线上下的所有元素都为零。涉及三角矩阵的线性方程组可以使用前代或回代方法轻松快捷地求解。
Cholesky 分解
Cholesky 分解将对称矩阵表示为三角矩阵与其转置的积
A = R′R,
其中,R 是上三角矩阵。
并非所有对称矩阵都可以通过这种方式进行分解;采用此类分解的矩阵被视为正定矩阵。这表明,A 的所有对角线元素都是正数,并且非对角线元素“不太大”。帕斯卡矩阵提供了有趣的示例。在本章中,示例矩阵 A 为 3×3 帕斯卡矩阵。暂时转换为 6×6:
1 | A = pascal(6) |
A 的元素为二项式系数。每个元素都是其北向和西向邻点之和。Cholesky 分解为
1 | R = chol(A) |
这些元素同样为二项式系数。R'*R 等于 A 的情况说明了涉及二项式系数的积之和的单位矩阵。
注意
Cholesky 分解也适用于复矩阵。采用 Cholesky 分解的任何复矩阵都满足
A′ = A
,并且被视为 Hermitian 正定矩阵。
通过 Cholesky 分解,可以将线性方程组
Ax = b
替换为
R′Rx = b。
由于反斜杠运算符能识别三角形方程组,因此这可以在 MATLAB 环境中通过以下表达式快速进行求解
1 | x = R\(R'\b) |
如果 A 为 n×n,则 chol(A) 的计算复杂度为 O(n3),但后续的反斜杠解的复杂度仅为 O(n2)。
LU 分解
LU 分解(或高斯消去法)将任何方阵 A 都表示为下三角矩阵和上三角矩阵的置换之积
A = LU,
其中,L 是对角线元素为 1 的下三角矩阵的置换,U 是上三角矩阵。
出于理论和计算原因,必须进行置换。矩阵
[0110]
在不交换其两行的情况下不能表示为三角矩阵的积。尽管矩阵
[ε110]
可以表示为三角矩阵之积,但当 ε 很小时,因子中的元素也会很大并且会增大误差,因此即使置换并非完全必要,它们也是所希望的。部分主元消去法可确保 L 的元素的模以 1 为限,并且 U 的元素并不大于 A 的元素。
例如:
1 | [L,U] = lu(B) |
通过对 A 执行 LU 分解,可以
1 | A*x = b |
使用以下表达式快速对线性方程组求解
1 | x = U\(L\b) |
行列式和逆矩阵是通过 LU 分解使用以下表达式进行计算的
1 | det(A) = det(L)*det(U) |
和
1 | inv(A) = inv(U)*inv(L) |
也可以使用 det(A) = prod(diag(U)) 计算行列式,但行列式的符号可能会相反。
QR 分解
正交矩阵或包含正交列的矩阵为实矩阵,其列全部具有单位长度并且相互垂直。如果 Q 为正交矩阵,则
QTQ = I,
其中 I 是单位矩阵。
最简单的正交矩阵为二维坐标旋转:
[cos(θ)−sin(θ)sin(θ)cos(θ)].
对于复矩阵,对应的术语为单位。由于正交矩阵和单位矩阵会保留长度、保留角度并且不会增大误差,因此适用于数值计算。
正交或 QR 分解将任何矩形矩阵表示为正交或酉矩阵与上三角矩阵的积。此外,也可能涉及列置换。
A = QR
或
AP = QR,
其中,Q 为正交或单位矩阵,R 为上三角矩阵,P 为置换向量。
QR 分解有四种变化形式 - 完全大小或合适大小,以及使用列置换或不使用列置换。
超定线性方程组涉及行数超过列数的矩形矩阵,也即 m×n 并且 m > n。完全大小的 QR 分解可生成一个方阵(m×m 正交矩阵 Q)和一个矩形 m×n 上三角矩阵 R:
1 | C=gallery('uniformdata',[5 4], 0); |
在许多情况下,Q 的最后 m – n 列是不需要的,因为这些列会与 R 底部的零相乘。因此,精简 QR 分解可生成一个矩形矩阵(具有正交列的 m×n Q)以及一个方阵 n×n 上三角矩阵 R。对于 5×4 示例,不会节省太多内存,但是对于更大的大量矩形矩阵,在时间和内存方面的节省可能会很重要:
1 | [Q,R] = qr(C,0) |
与 LU 分解相比,QR 分解不需要进行任何消元或置换。但是,可选的列置换(因存在第三个输出参数而触发)对检测奇异性或秩亏是很有帮助的。在分解的每一步,未分解的剩余矩阵的列(范数最大)将用作该步骤的基础。这可以确保 R 的对角线元素以降序排列,并且各列之间的任何线性相关性肯定能够通过检查这些元素来显示。对于此处提供的小示例,C 的第二列的范数大于第一列的范数,因此这两列被交换:
1 | [Q,R,P] = qr(C) |
组合了合适大小和列置换后,第三个输出参数为置换向量而不是置换矩阵:
1 | [Q,R,p] = qr(C,0) |
QR 分解可将超定线性方程组转换为等效的三角形方程组。表达式
1 | norm(A*x - b) |
等于
1 | norm(Q*R*x - b) |
与正交矩阵相乘可保留欧几里德范数,因此该表达式也等于
1 | norm(R*x - y) |
其中 y = Q'*b。由于 R 的最后 m-n 行为零,因此该表达式将分为两部分:
1 | norm(R(1:n,1:n)*x - y(1:n)) |
并且
1 | norm(y(n+1:m)) |
如果 A 具有满秩,则可以对 x 求解,使这些表达式中的第一个表达式为零。然后,第二个表达式便可以提供残差范数。如果 A 没有满秩,则可以通过 R 的三角形结构体对最小二乘问题求基本解。
对分解使用多线程计算
对于许多线性代数函数和按元素的数值函数,MATLAB 软件支持多线程计算。这些函数将自动在多个线程上执行。要使函数或表达式在多个 CPU 上更快地执行,必须满足许多条件:
- 函数执行的运算可轻松划分为并发执行的多个部分。这些部分必须能够在进程之间几乎不通信的情况下执行。它们应需要很少的序列运算。
- 数据大小足以使并发执行的任何优势在重要性方面超过对数据分区和管理各个执行线程所需的时间。例如,仅当数组包含数千个或以上的元素时,大多数函数才会加速。
- 运算未与内存绑定;处理时间不受内存访问时间控制。一般而言,复杂函数比简单函数速度更快。
对于大型双精度数组(约 10,000 个元素),lu 和 qr 会大幅增加速度。
另请参阅
相关主题
4. 幂和指数
尝试此示例Copy Command Copy Code
本主题说明如何使用各种方法计算矩阵幂和指数。
正整数幂
如果 A 为方阵并且 p 为正整数,则 A^p 实际上是将 A 乘以其自身 p-1 次。例如:
1 | A = [1 1 1 |
逆幂和分数幂
如果 A 为方阵并且是非奇异的,则 A^(-p) 实际上是将 inv(A) 乘以其自身 p-1 次。
1 | A^(-3) |
MATLAB® 用相同的算法计算 inv(A) 和 A^(-1),因此结果完全相同。如果矩阵接近奇异,inv(A) 和 A^(-1) 都会发出警告。
1 | isequal(inv(A),A^(-1)) |
也允许分数幂,例如 A^(2/3)。使用小数幂的结果取决于矩阵特征值的分布。
1 | A^(2/3) |
逐元素幂
.^ 运算符计算逐元素幂。例如,要对矩阵中的每个元素求平方,可以使用 A.^2。
1 | A.^2 |
平方根
使用 sqrt 函数可以方便地计算矩阵中每个元素的平方根。另一种方法是 A.^(1/2)。
1 | sqrt(A) |
对于其他根,您可以使用 nthroot。例如,计算 A.^(1/3)。
1 | nthroot(A,3) |
这些按元素计算的根不同于矩阵平方根,后者计算得到的是另一个矩阵 B 以满足 A=BB。函数 sqrtm(A) 采用更精确的算法计算 A^(1/2)。sqrtm 中的 m 将此函数与 sqrt(A) 区分开来,后者与 A.^(1/2) 一样,以逐元素方式工作。
1 | B = sqrtm(A) |
标量底
除了对矩阵求幂以外,您还可以以矩阵为次数对标量求幂。
1 | 2^A |
当您以矩阵为次数对标量求幂时,MATLAB 使用矩阵的特征值和特征向量来计算矩阵幂。如果 [V,D] = eig(A),则 2A=V 2D V−1。
1 | [V,D] = eig(A); |
矩阵指数
矩阵指数是以矩阵为次数对标量求幂的特殊情况。矩阵指数的底是欧拉数 e = exp(1)。
1 | e = exp(1); |
expm 函数是计算矩阵指数的一种更方便的方法。
1 | expm(A) |
矩阵指数可以用多种方法来计算。有关详细信息,请参阅 矩阵指数。
处理较小的数字
对于非常小的 x 值,MATLAB 函数 log1p 和 expm1 可以精确计算 log(1+x) 和 e**x−1。例如,如果您尝试将小于计算机精度的一个数与 1 相加,则结果会舍入到 1。
1 | log(1+eps/2) |
但是,log1p 能够返回更准确的答案。
1 | log1p(eps/2) |
同样,对于 e**x−1,如果 x 非常小,则会将它舍入为零。
1 | exp(eps/2)-1 |
同样,expm1 能够返回更准确的答案。
1 | expm1(eps/2) |
另请参阅
exp | expm | expm1 | power | mpower | sqrt | sqrtm | nthroot
相关主题
5. 特征值
特征值的分解
方阵 A 的特征值和特征向量分别为满足以下条件的标量 λ 和非零向量 υ
Aυ = λυ。
对于对角矩阵的对角线上的特征值 Λ 以及构成矩阵列的对应特征向量 V,公式为
AV = VΛ。
如果 V 是非奇异的,这将变为特征值分解。
A = VΛV–1。
微分方程 dx/dt = Ax 的系数矩阵就是一个很好的示例:
1 | A = |
此方程的解用矩阵指数 x(t) = etAx(0) 表示。语句
1 | lambda = eig(A) |
生成包含 A 的特征值的列向量。对于该矩阵,这些特征值为复数:
1 | lambda = |
每个特征值的实部都为负数,因此随着 t 的增加,eλt 将会接近零。两个特征值 ±ω 的非零虚部为微分方程的解提供了振动分量 sin(ωt)。
使用这两个输出参数,eig 便可以计算特征向量并将特征值存储在对角矩阵中:
1 | [V,D] = eig(A) |
第一个特征向量为实数,另外两个向量互为共轭复数。所有三个向量都归一化为具有等于 1 的欧几里德长度 norm(v,2)。
矩阵 V*D*inv(V)(可更简洁地写为 V*D/V)位于 A 的舍入误差界限内。inv(V)*A*V 或 V\A*V 都在 D 的舍入误差界限内。
多重特征值
某些矩阵没有特征向量分解。这些矩阵是不可对角化的。例如:
1 | A = [ 1 -2 1 |
对于此矩阵
1 | [V,D] = eig(A) |
生成
1 | V = |
λ =1 时有一个双精度特征值。V 的第一列和第二列相同。对于此矩阵,并不存在一组完整的线性无关特征向量。
Schur 分解
许多高级矩阵计算不需要进行特征值分解。而是使用 Schur 分解。
A = USU ′ ,
其中,U 是正交矩阵,S 是对角线上为 1×1 和 2×2 块的块上三角矩阵。特征值是通过 S 的对角元素和块显示的,而 U 的列提供了正交基,它的数值属性要远远优于一组特征向量。
例如,比较下面的亏损矩阵的特征值和 Schur 分解:
1 | A = [ 6 12 19 |
矩阵 A 为亏损矩阵,因为它不具备一组完整的线性无关特征向量(V 的第二列和第三列相同)。由于 V 的列并非全部是线性无关的,因此它有一个很大的条件数,大约为 1e8。但 schur 可以计算 U 中的三个不同基向量。由于 U 是正交矩阵,因此 cond(U) = 1。
矩阵 S 的实数特征值作为对角线上的第一个条目,并通过右下方的 2×2 块表示重复的特征值。2×2 块的特征值也是 A 的特征值:
1 | eig(S(2:3,2:3)) |
另请参阅
相关主题
6. 奇异值
矩形矩阵 A 的奇异值和对应的奇异向量分别为满足以下条件的标量 σ 以及一对向量 u 和 v
A**v=σuAHu=σ**v,
其中 A**H 是 A 的 Hermitian 转置。奇异向量 u 和 v 通常缩放至范数为 1。此外,如果 u 和 v 均为 A 的奇异向量,则 -u 和 -v 也为 A 的奇异向量。
奇异值 σ 始终为非负实数,即使 A 为复数也是如此。对于对角矩阵 Σ 中的奇异值以及构成两个正交矩阵 U 和 V 的列的对应奇异向量,方程为
A**V=UΣAHU=VΣ.
由于 U 和 V 均为单位矩阵,因此将第一个方程的右侧乘以 V**H 会生成奇异值分解方程
A=UΣV**H.
m×n 矩阵的完整奇异值分解涉及:
- m×m 矩阵 U
- m×n 矩阵 Σ
- n×n 矩阵 V
换句话说,U 和 V 均为方阵,Σ 与 A 的大小相同。如果 A 的行数远多于列数 (m > n),则得到的 m×m 矩阵 U 为大型矩阵。但是,U 中的大多数列与 Σ 中的零相乘。在这种情况下,精简分解可通过生成一个 m×n U、一个 n×n Σ 以及相同的 V 来同时节省时间和存储空间:
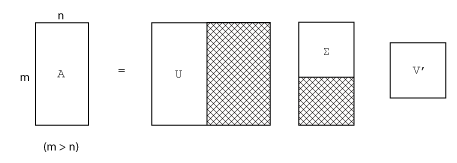
特征值分解是分析矩阵(当矩形表示从向量空间到其自身的映射时)的合适工具,就像分析常微分方程一样。但是,奇异值分解是分析从一个向量空间到另一个向量空间(可能具有不同的维度)的映射的合适工具。大多数联立线性方程组都属于这第二类。
如果 A 是方形的对称正定矩阵,则其特征值分解和奇异值分解相同。但是,当 A 偏离对称性和正定性时,这两种分解之间的差异就会增加。特别是,实矩阵的奇异值分解始终为实数,但非对称实矩阵的特征值分解可能为复数。
对于示例矩阵
1 | A = |
完整的奇异值分解为
1 | [U,S,V] = svd(A) |
可以验证 U*S*V' 在舍入误差界限内是否等于 A。对于此类小问题,精简分解只是略小一些。
1 | [U,S,V] = svd(A,0) |
同样,U*S*V' 在舍入误差界限内等于 A。
分批 SVD 计算
如果需要分解一个由大小相同的矩阵组成的大型矩阵集合,则用 svd 在循环中执行所有分解是低效的。在这种情况下,您可以将所有矩阵串联成一个多维数组,并使用 pagesvd 通过一次函数调用对所有数组页执行奇异值分解。
| 函数 | 用法 |
|---|---|
pagesvd |
使用 pagesvd 对多维数组的页执行奇异值分解。这是对大小相同的矩阵组成的大型集合执行 SVD 的高效方法。 |
例如,假设有一个包含三个 2×2 矩阵的集合。使用 cat 函数将这些矩阵串联成一个 2×2×3 数组。
1 | A = [0 -1; 1 0]; |
现在,使用 pagesvd 同时执行三个分解。
1 | [U,S,V] = pagesvd(X); |
对于 X 的每页,输出 U、S 和 V 中都有对应的页。例如,矩阵 A 位于 X 的第一页上,其分解由 U(:,:,1)*S(:,:,1)*V(:,:,1)' 给出。
低秩 SVD 逼近
对于大型稀疏矩阵,使用 svd 计算所有奇异值和奇异向量并不始终可行。例如,如果您只需知道几个最大的奇异值,那么计算一个 5000×5000 稀疏矩阵的所有奇异值会带来额外的工作。
在只需要一部分奇异值和奇异向量的情况下,svds 和 svdsketch 函数优先于 svd。
| 函数 | 用法 |
|---|---|
svds |
使用 svds 计算 SVD 的 k 秩逼近。您可以指定一部分奇异值应为最大值、最小值还是最接近特定数字的值。svds 通常计算最可能的 k 秩逼近。 |
svdsketch |
使用 svdsketch 计算输入矩阵的满足指定容差的部分 SVD。svds 要求您指定秩,而 svdsketch 根据指定的容差以自适应方式确定矩阵草图的秩。svdsketch 最终使用的 k 秩逼近满足容差,但不同于 svds,它无法保证是最佳的。 |
例如,假设有一个密度约为 30% 的 1000×1000 随机稀疏矩阵。
1 | n = 1000; |
最大的六个奇异值为
1 | S = svds(A) |
此外,最小的六个奇异值为
1 | S = svds(A,6,'smallest') |
对于可作为满矩阵 full(A) 载入内存的较小矩阵,使用 svd(full(A)) 的速度可能仍快于使用 svds 或 svdsketch。但对于确实很大的稀疏矩阵,就有必要使用 svds 或 svdsketch。
另请参阅
svd | svds | svdsketch | gsvd | pagesvd




