
Kaggle入门(以Titanic项目为例)
一.简介
本篇会以Titanic的模型为例,熟悉Kaggle网站的使用和项目的复现。本篇会分别介绍云端和本地运行项目的方式。
前提准备:
二. 网页运行
注册Kaggle账号(自行注册)
打开Titanic项目
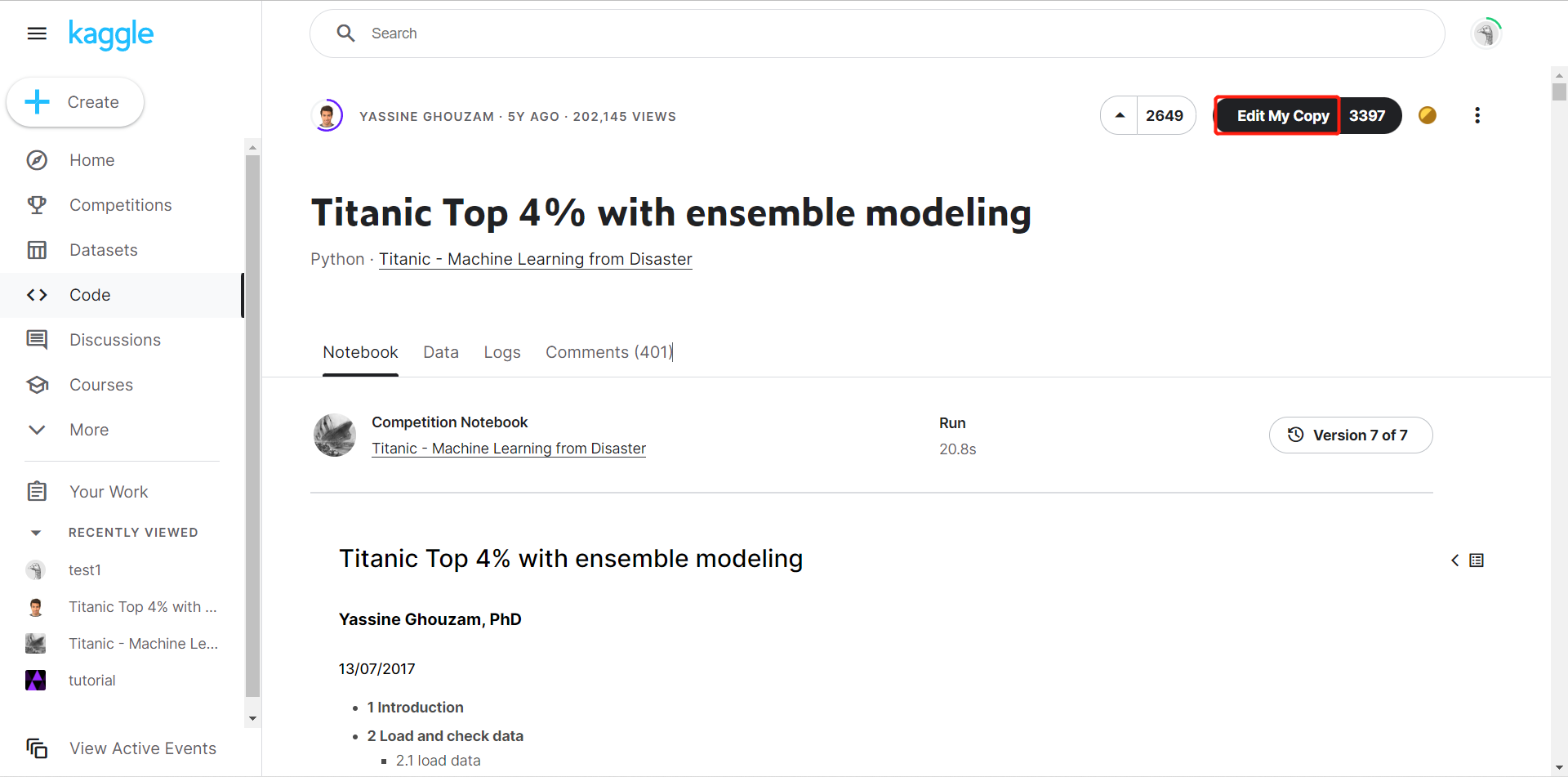
选择Edit
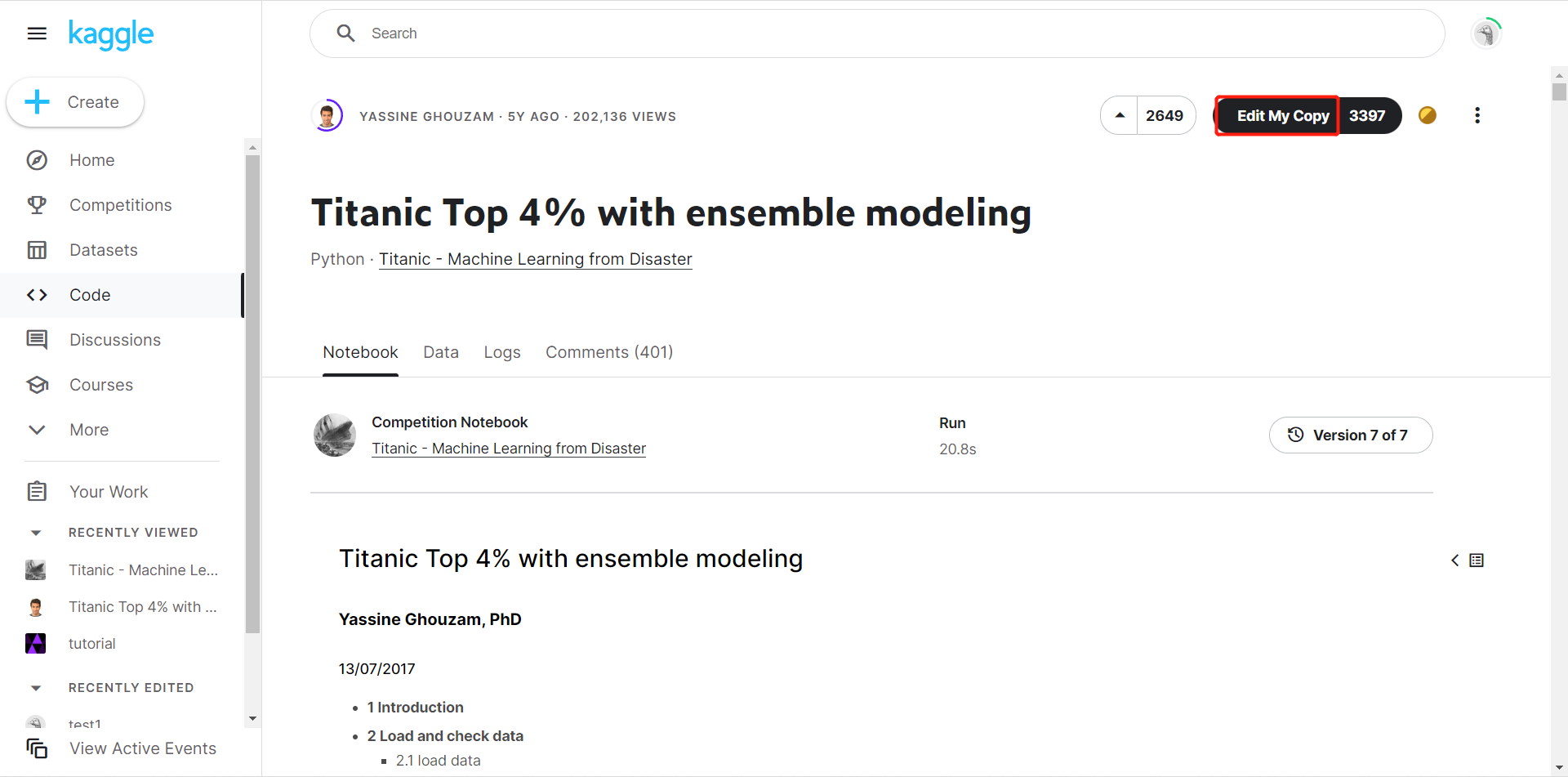
可在左上角修改项目的名字
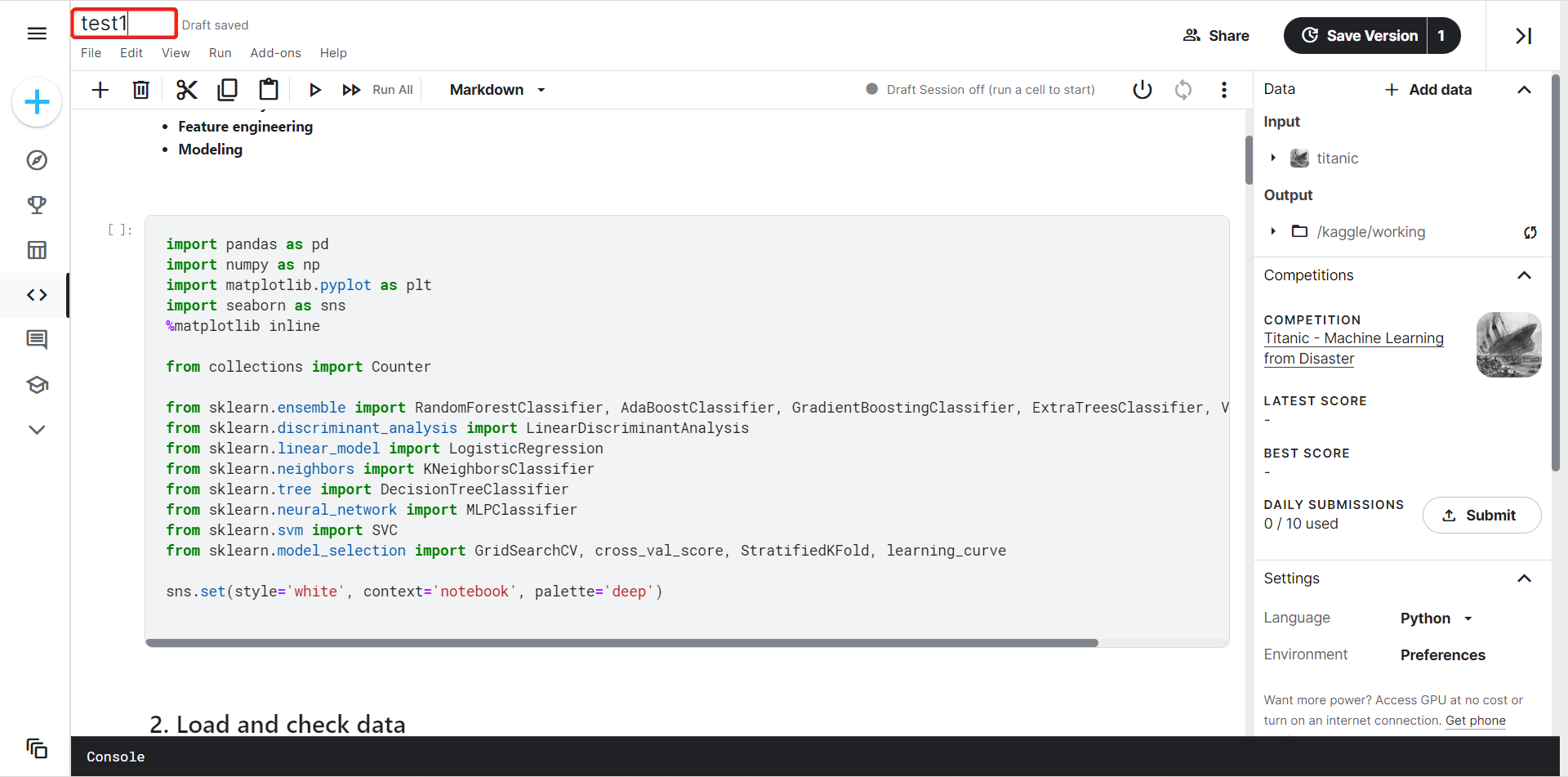
选择Run All运行所有代码
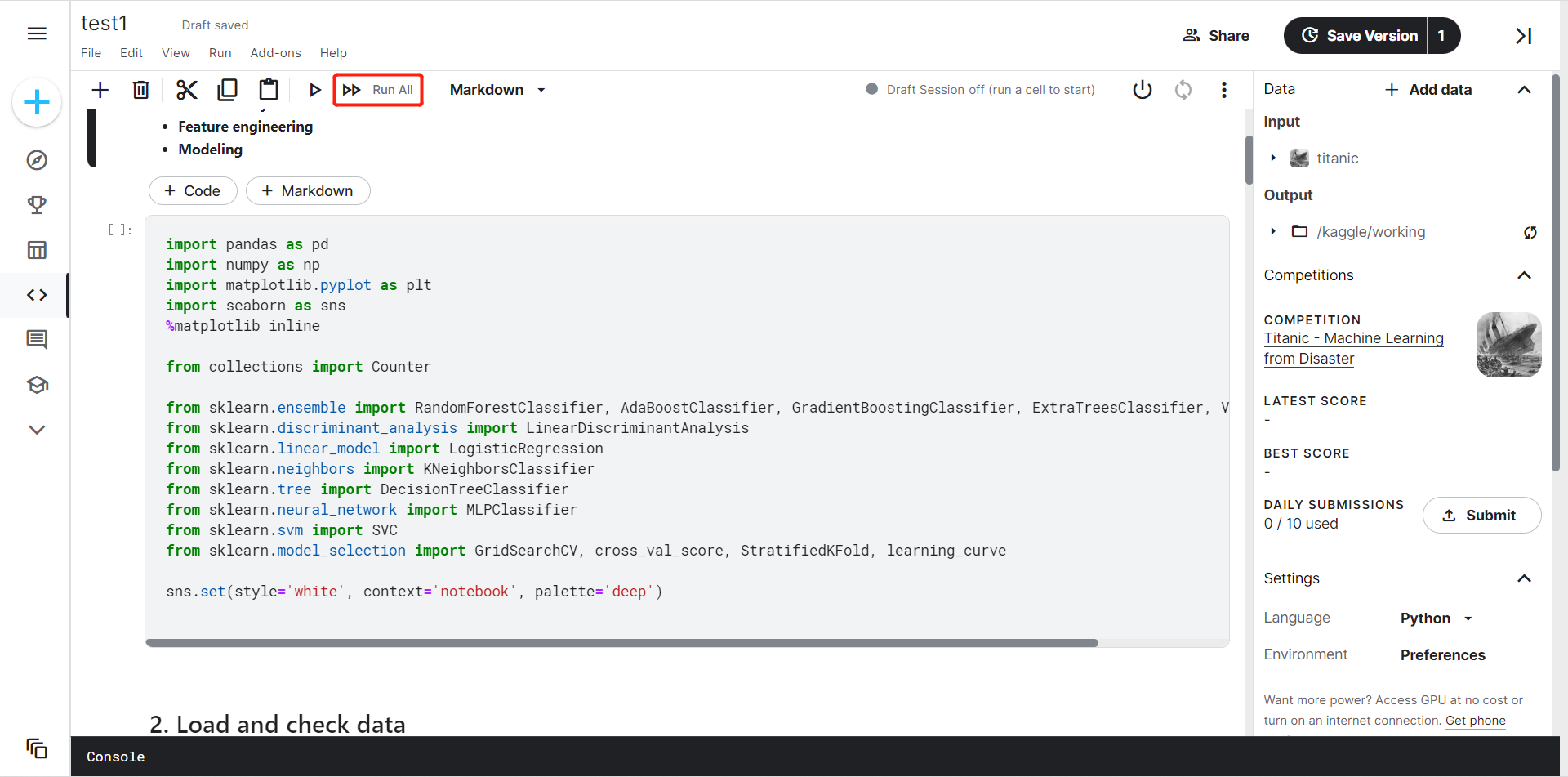
选择Save Version保存到自己的Notebook
可自定义项目名,保存后项目会自动运行所有代码
在侧边栏选择Your Work找到刚刚保存的项目
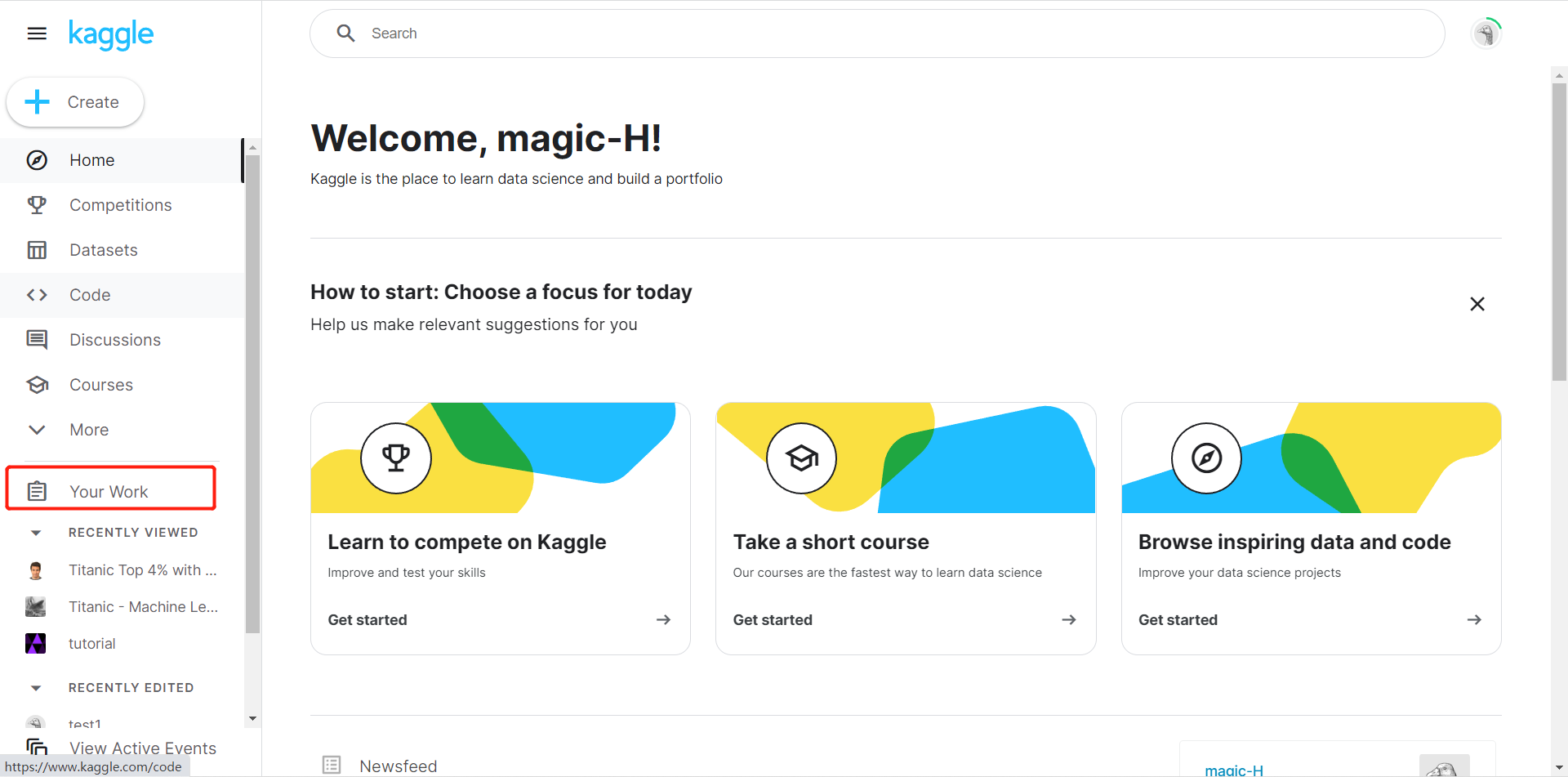
选择Code
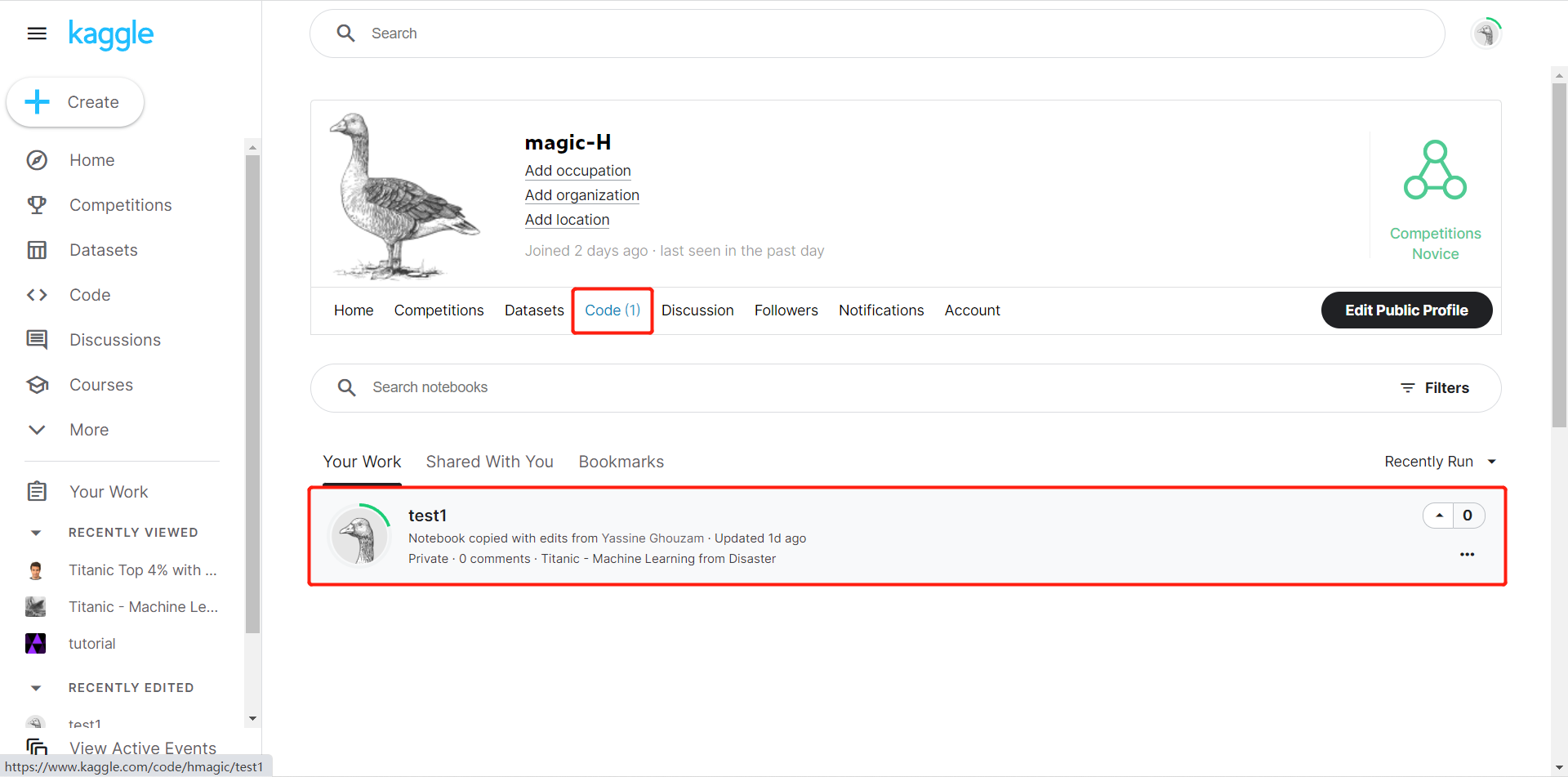
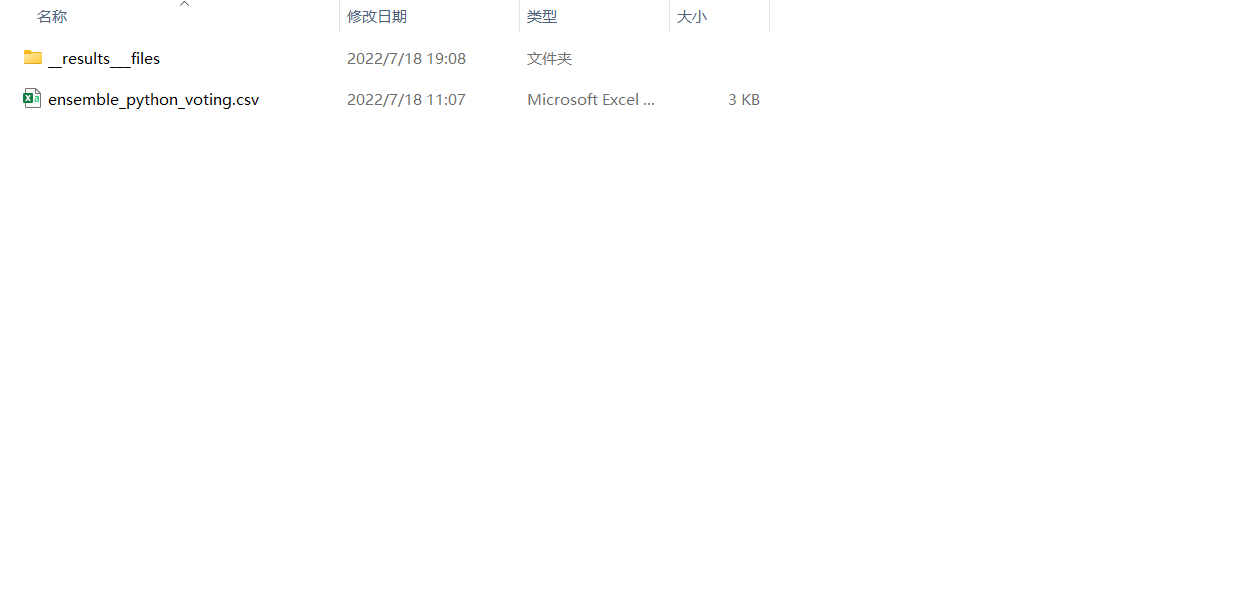
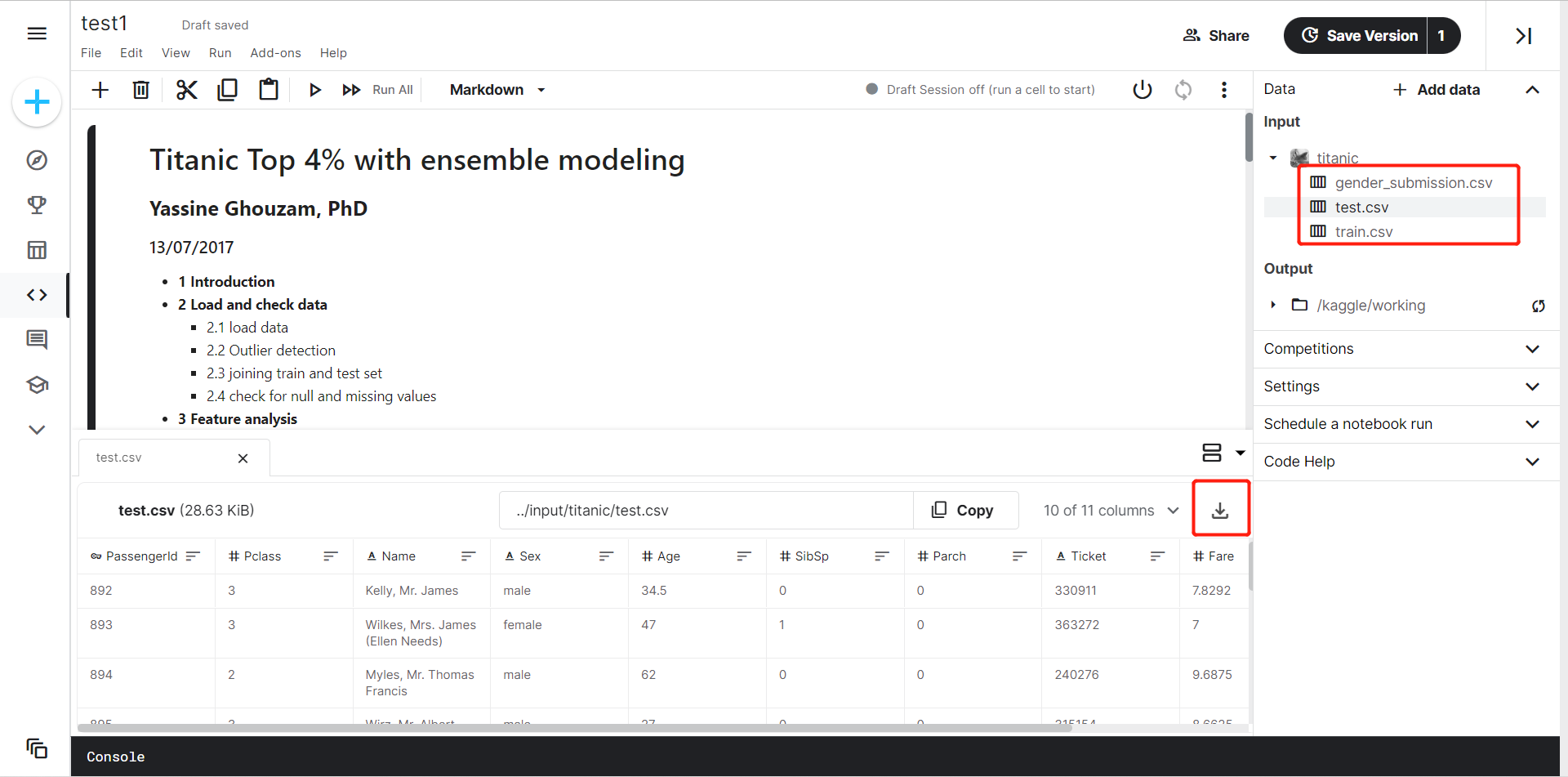
选择刚刚保存的项目,点击Data,看到Output选择下载就可以保存生成的图片及日志
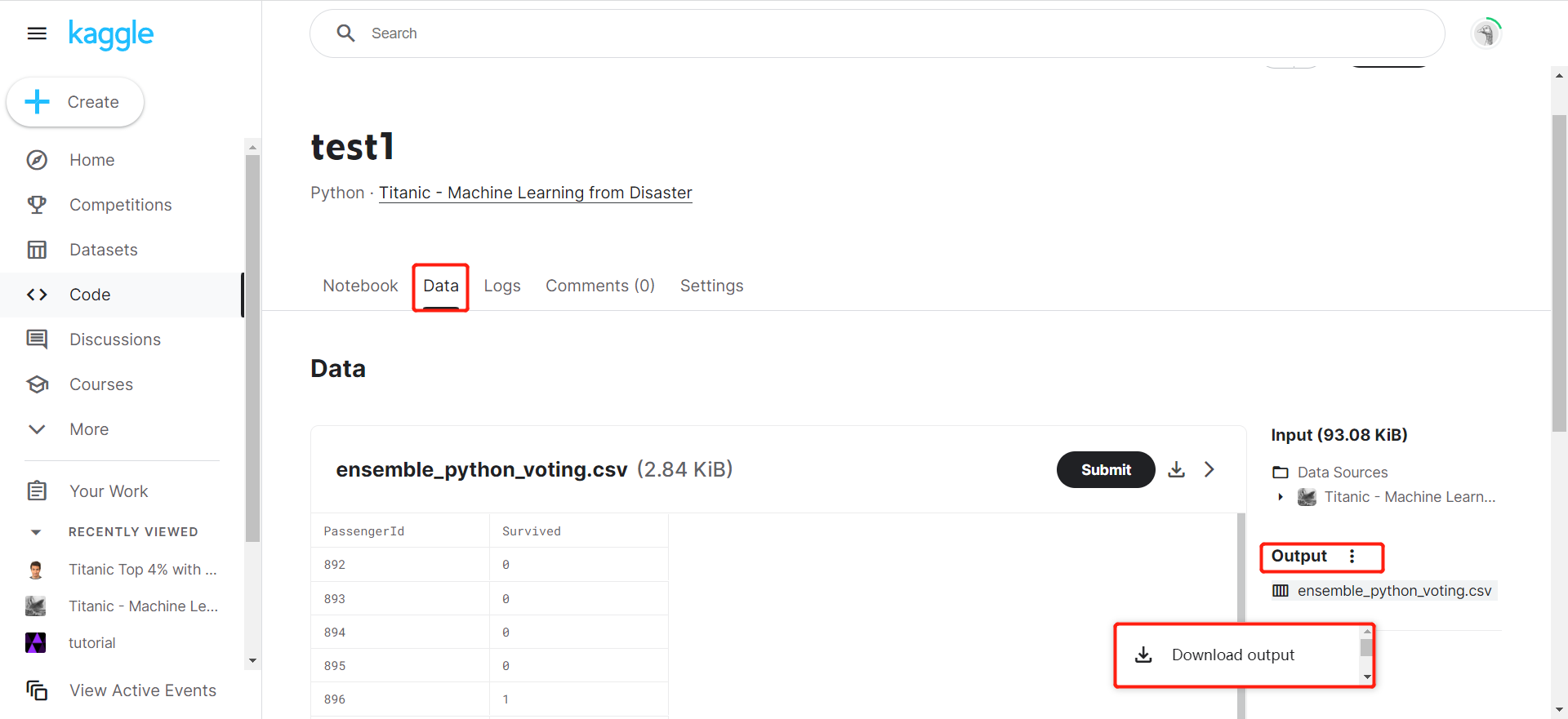
将下载的压缩包解压,打开文件夹
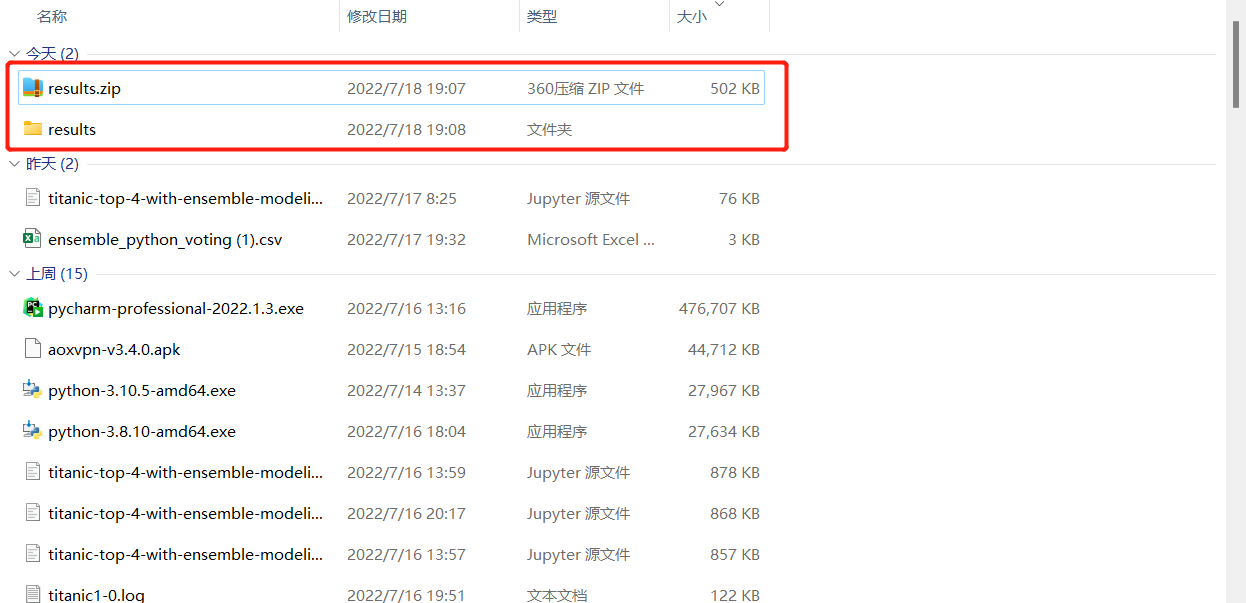
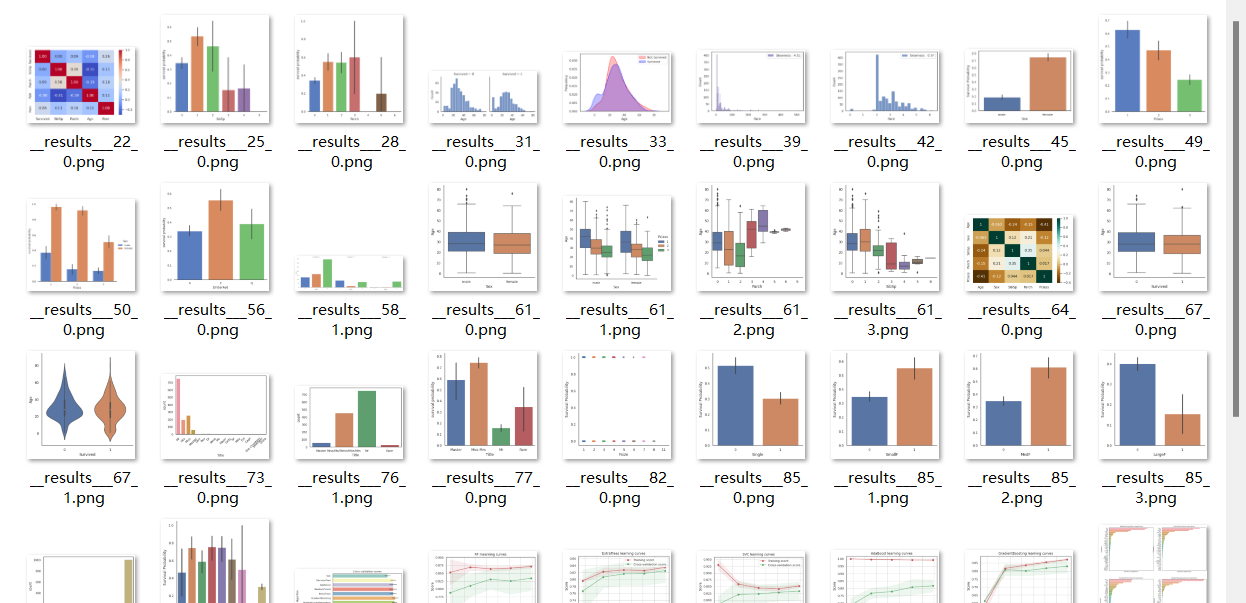
生成的图片在_results__files里面
完结撒花
三.本地运行- 打开Titanic项目,选择Edit
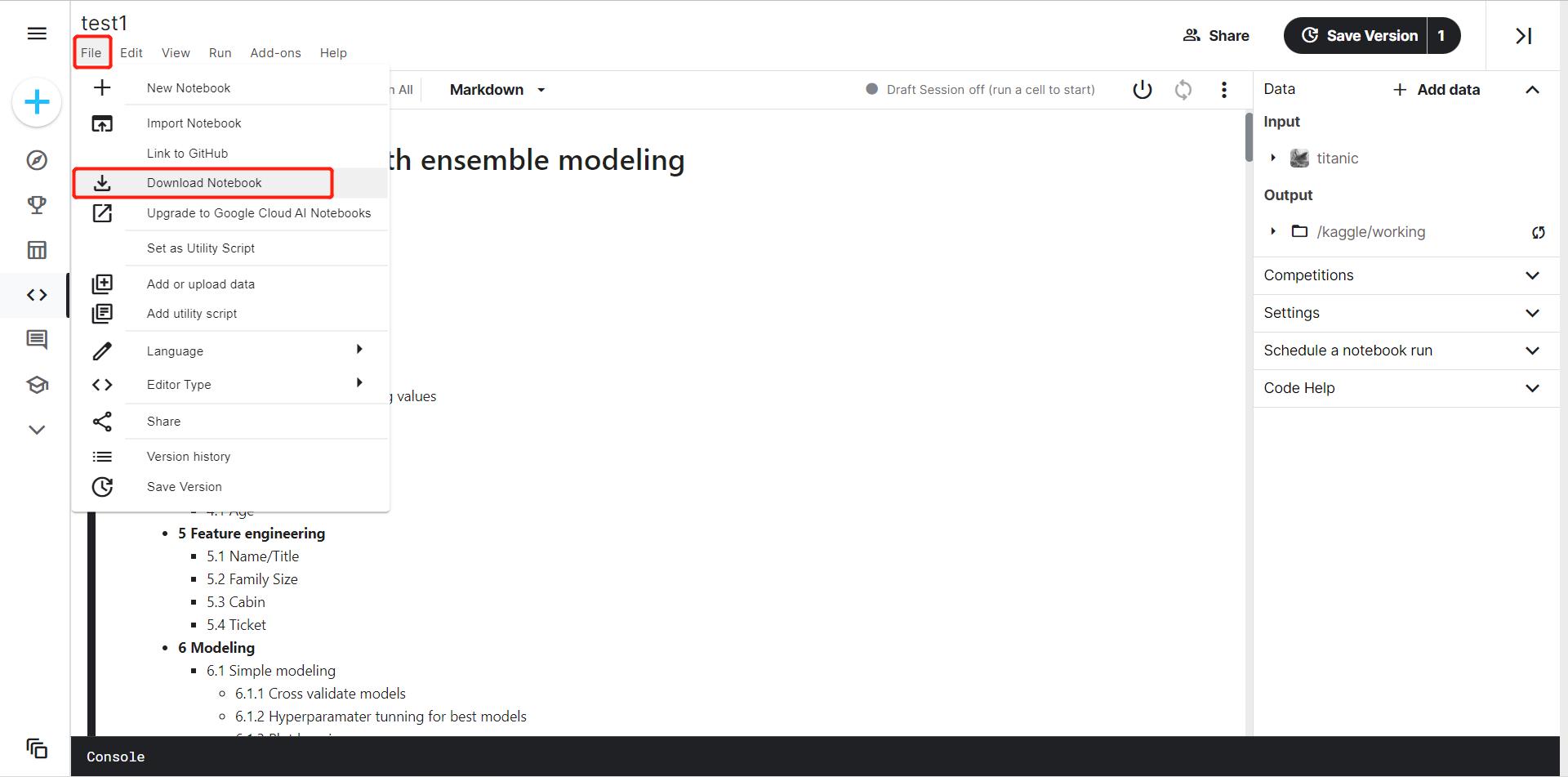
下载代码和数据集
下载全部数据集
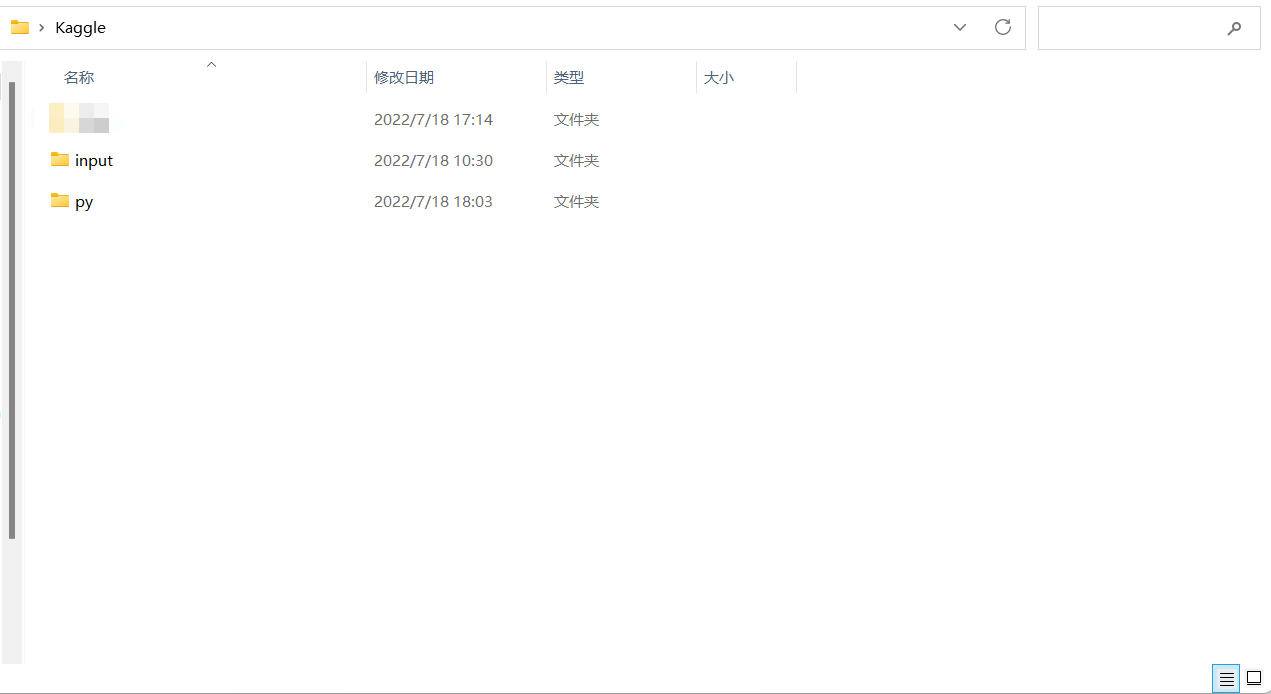
创建文件夹,放置代码和数据集
因为在源代码中,数据集的路径为“../input/train.csv”
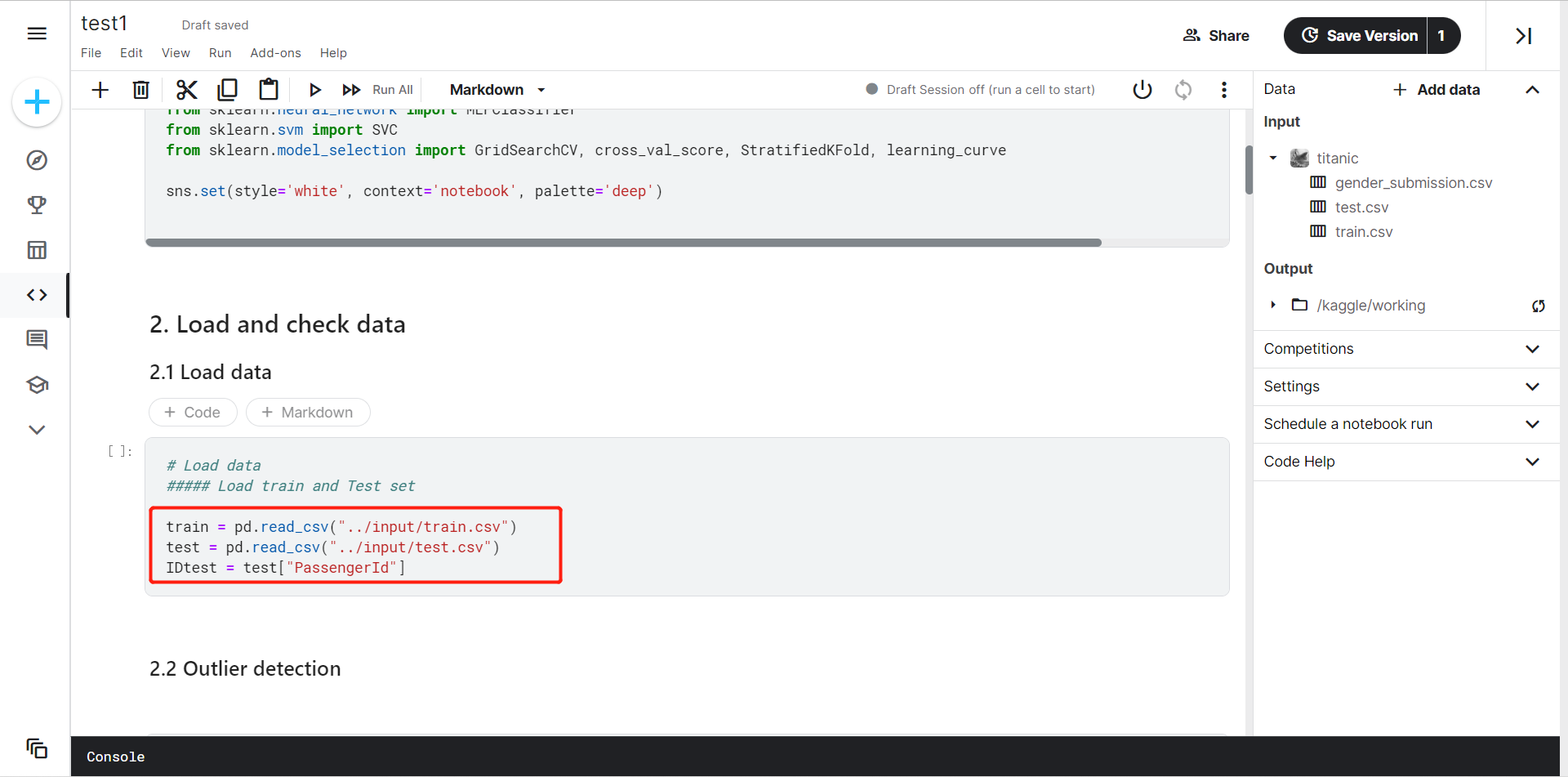
由此我创建以下结构的文件夹,将数据集都放在input里面,将源代码放入py里面
准备环境,下载Jupyter和Python需要的模块(请确保已经有Python环境)
按Win+R,输入cmd然后回车,打开cmd
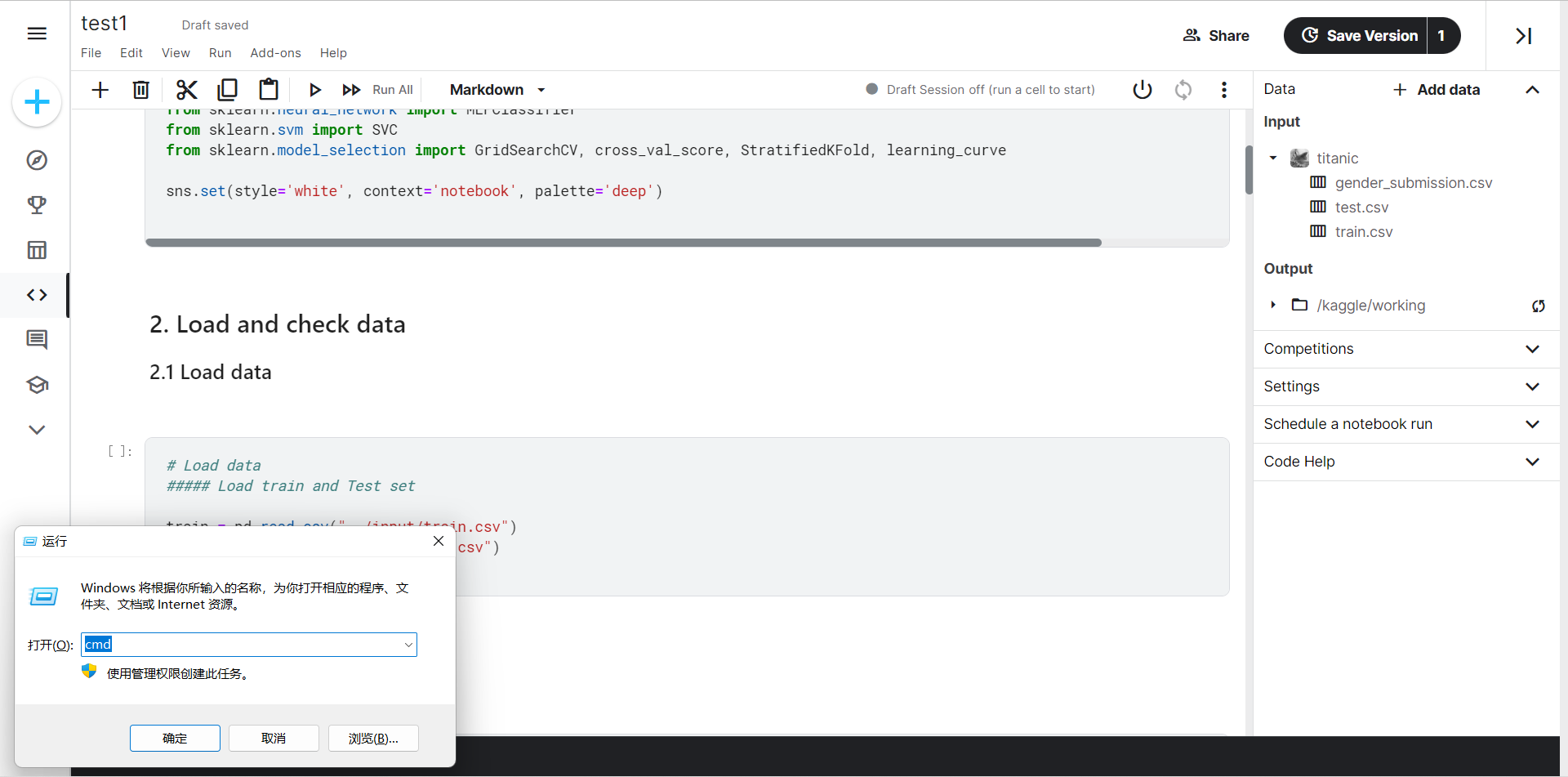
输入以下命令
1
pip install jupyterlab
1
pip install jupyter notebook
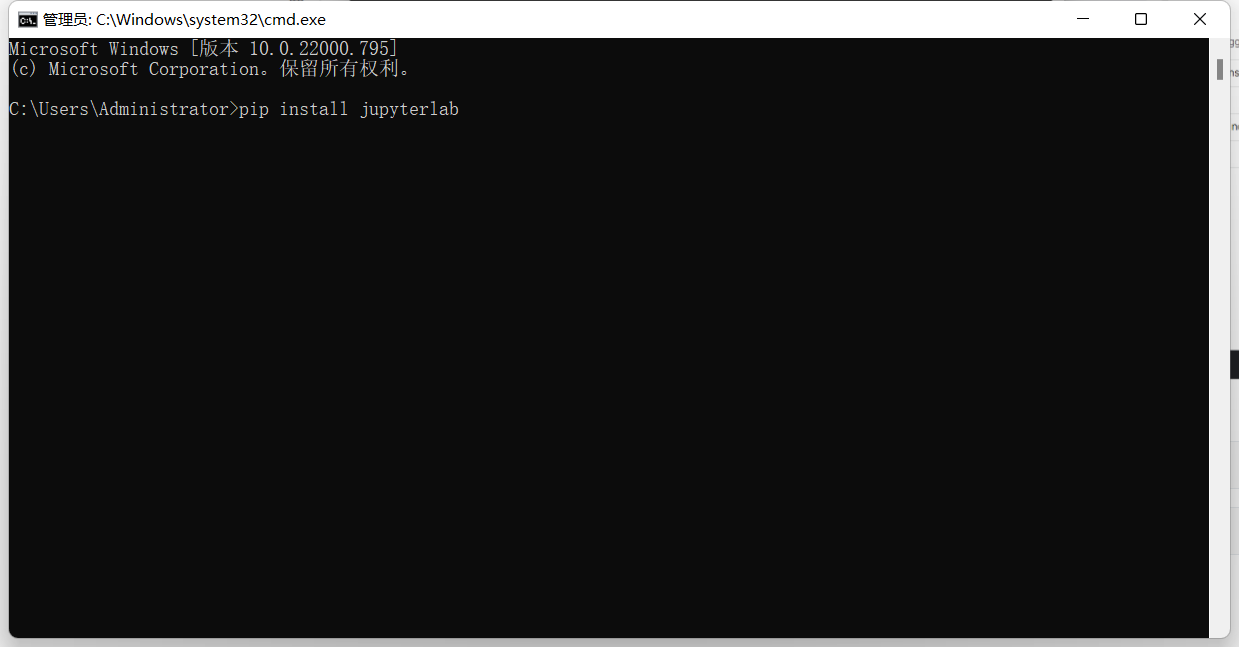
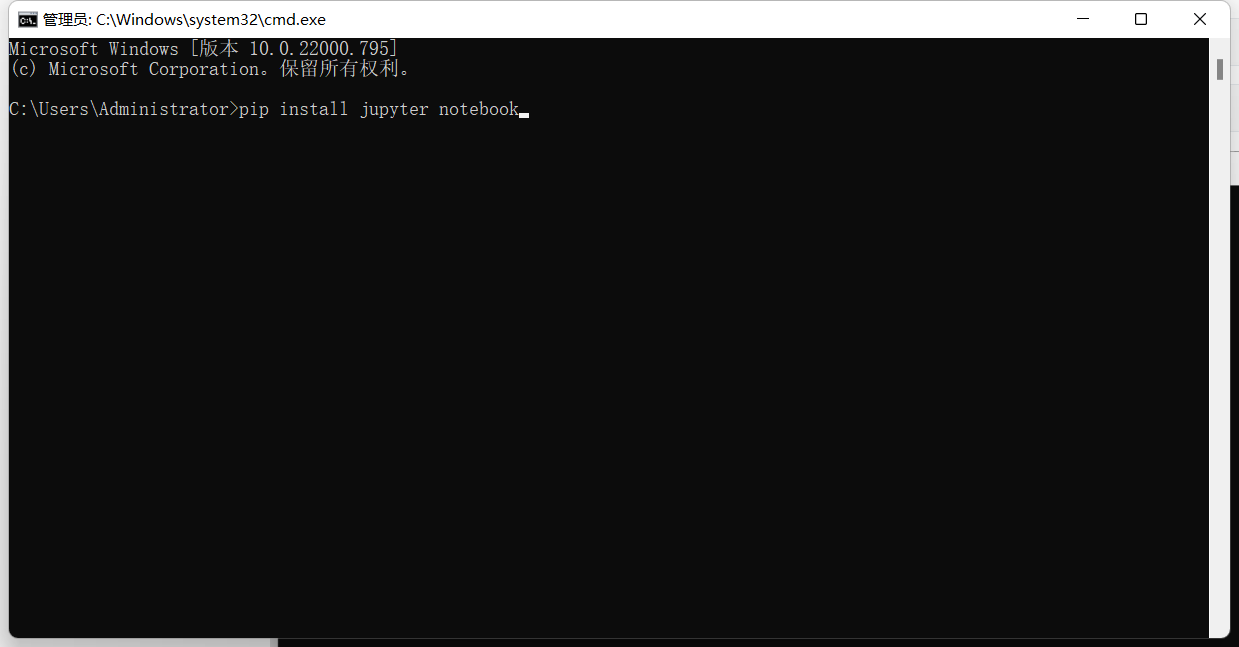
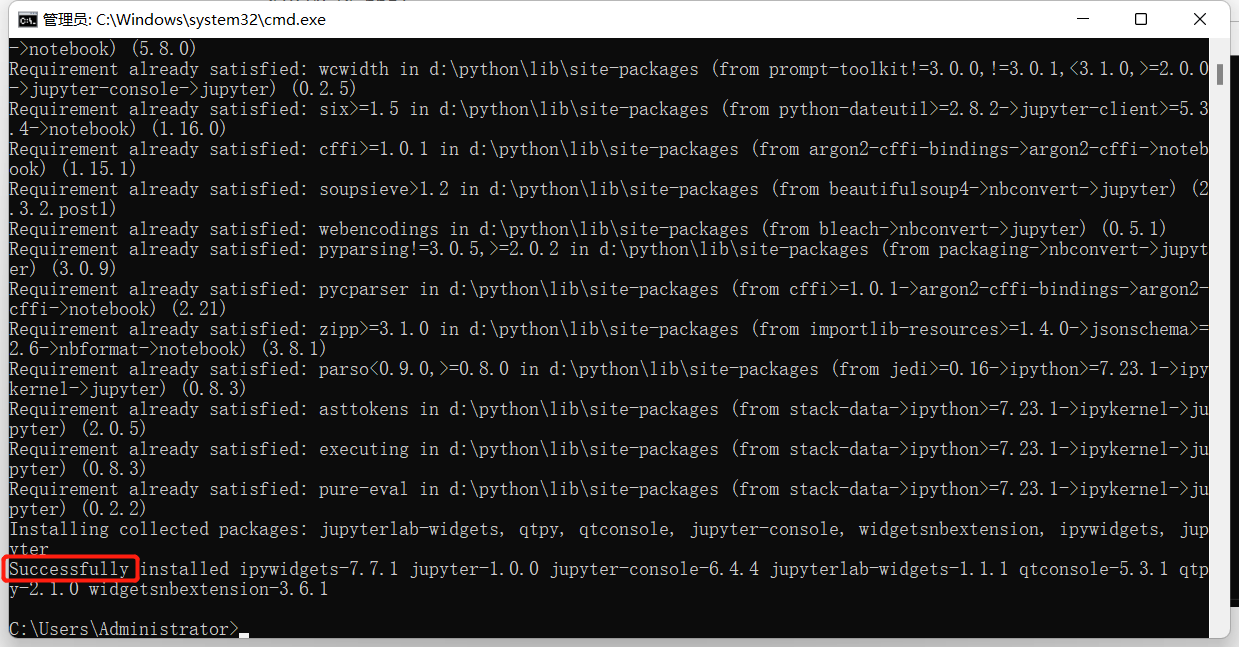
两次安装都能看见Successful即为安装成功
将项目的文件夹拖入Pycharm打开

红色波浪线的模块为未安装的模块,可以直接选择安装
也可以在cmd中使用pip install + 模块名的方式安装
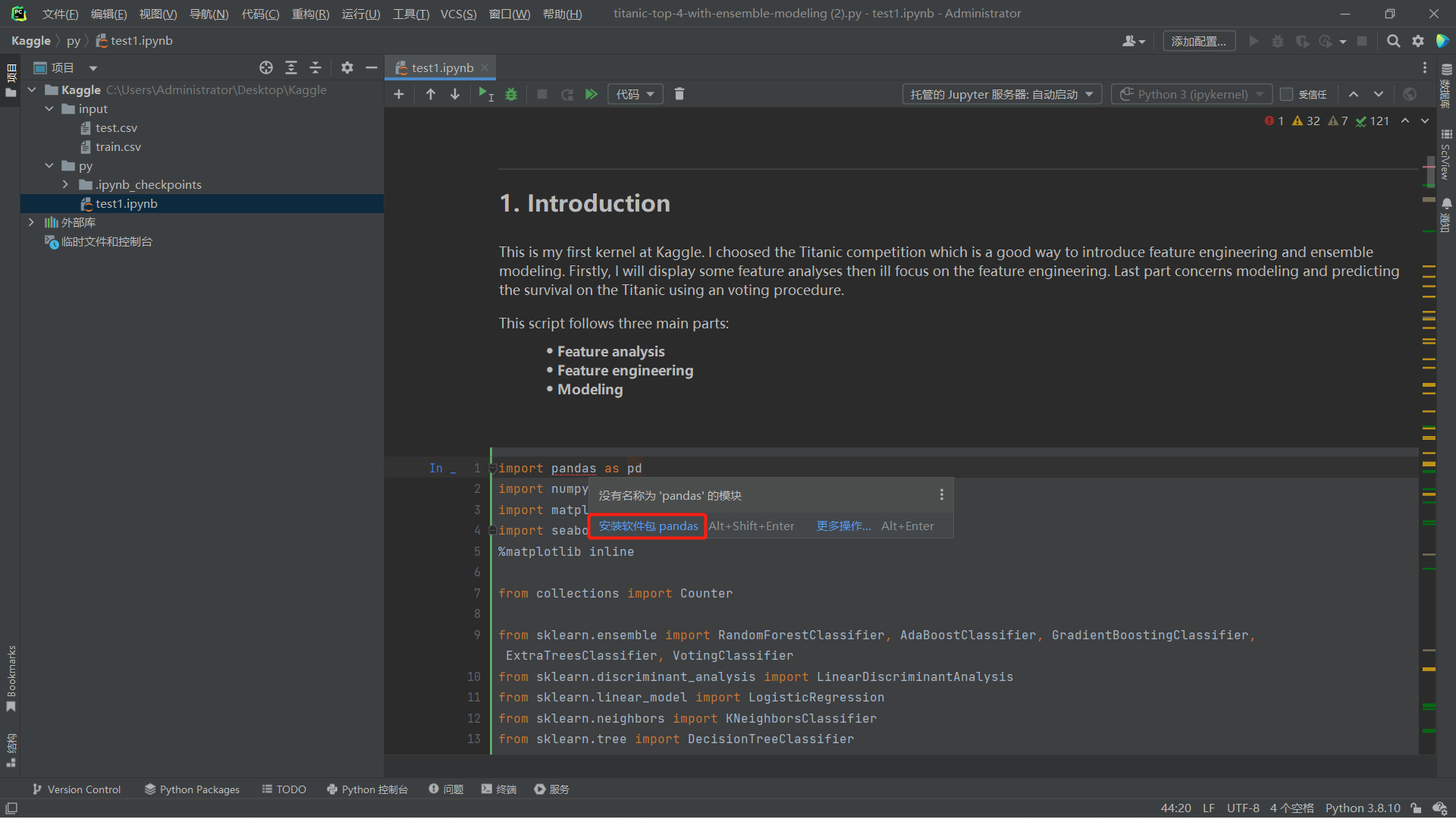
两种运行方式
使用Pycharm运行
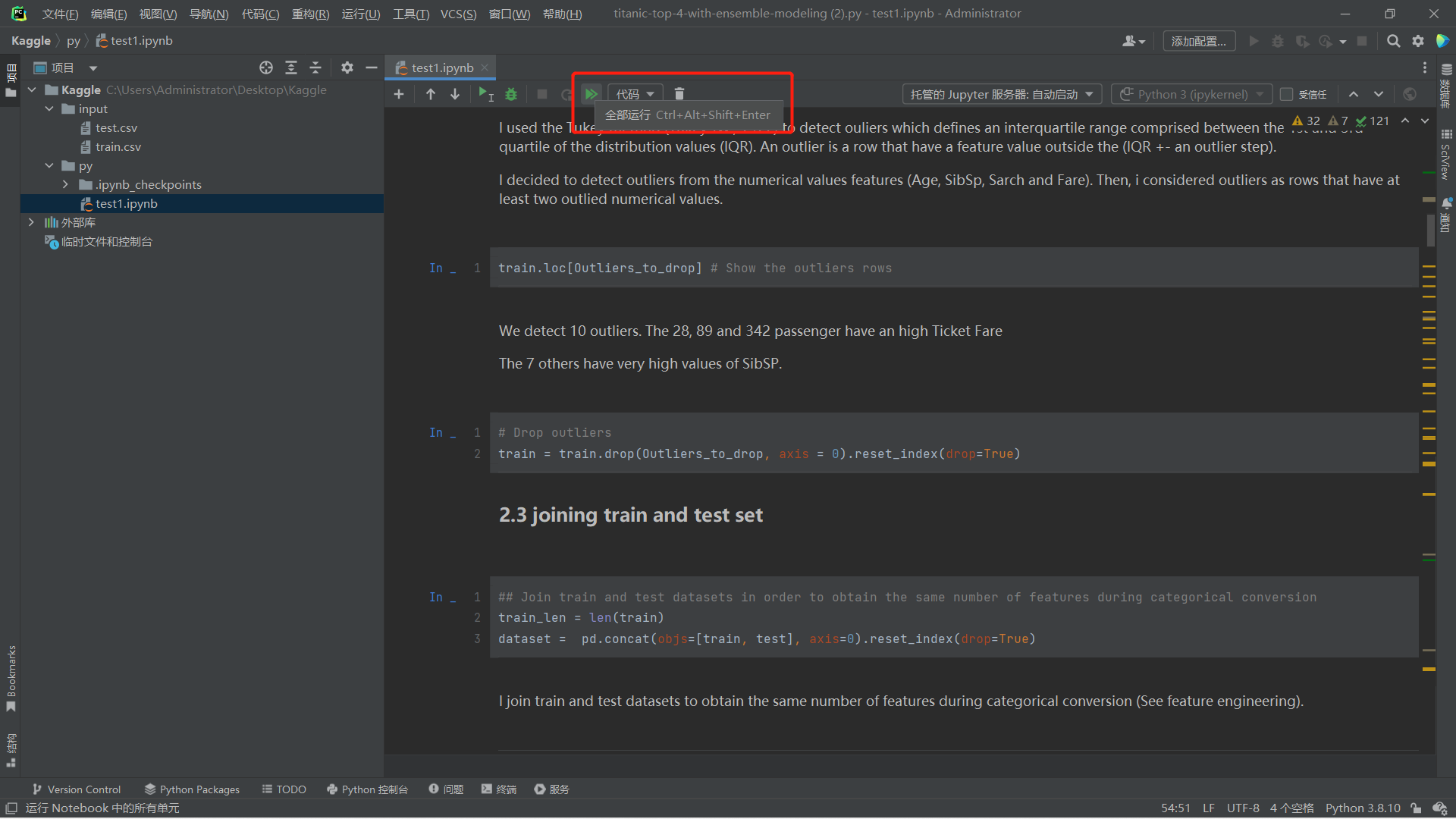
使用Jupyter运行
打开cmd输入jupyter notebook
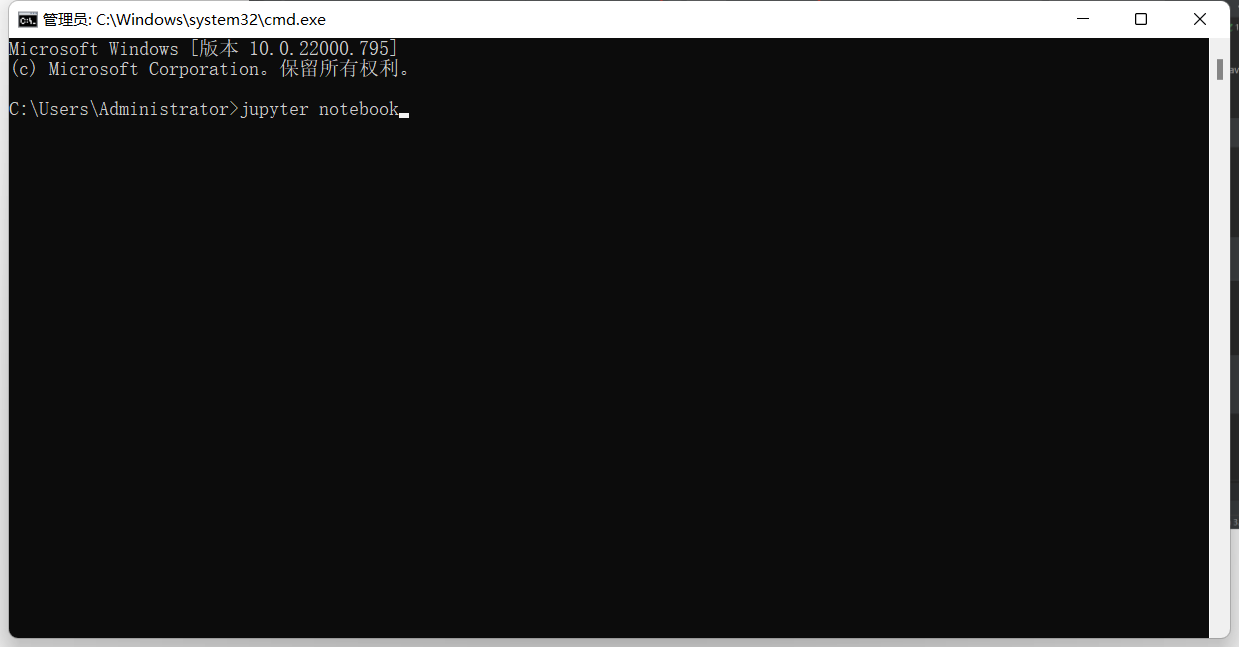
这时会自动跳转网页
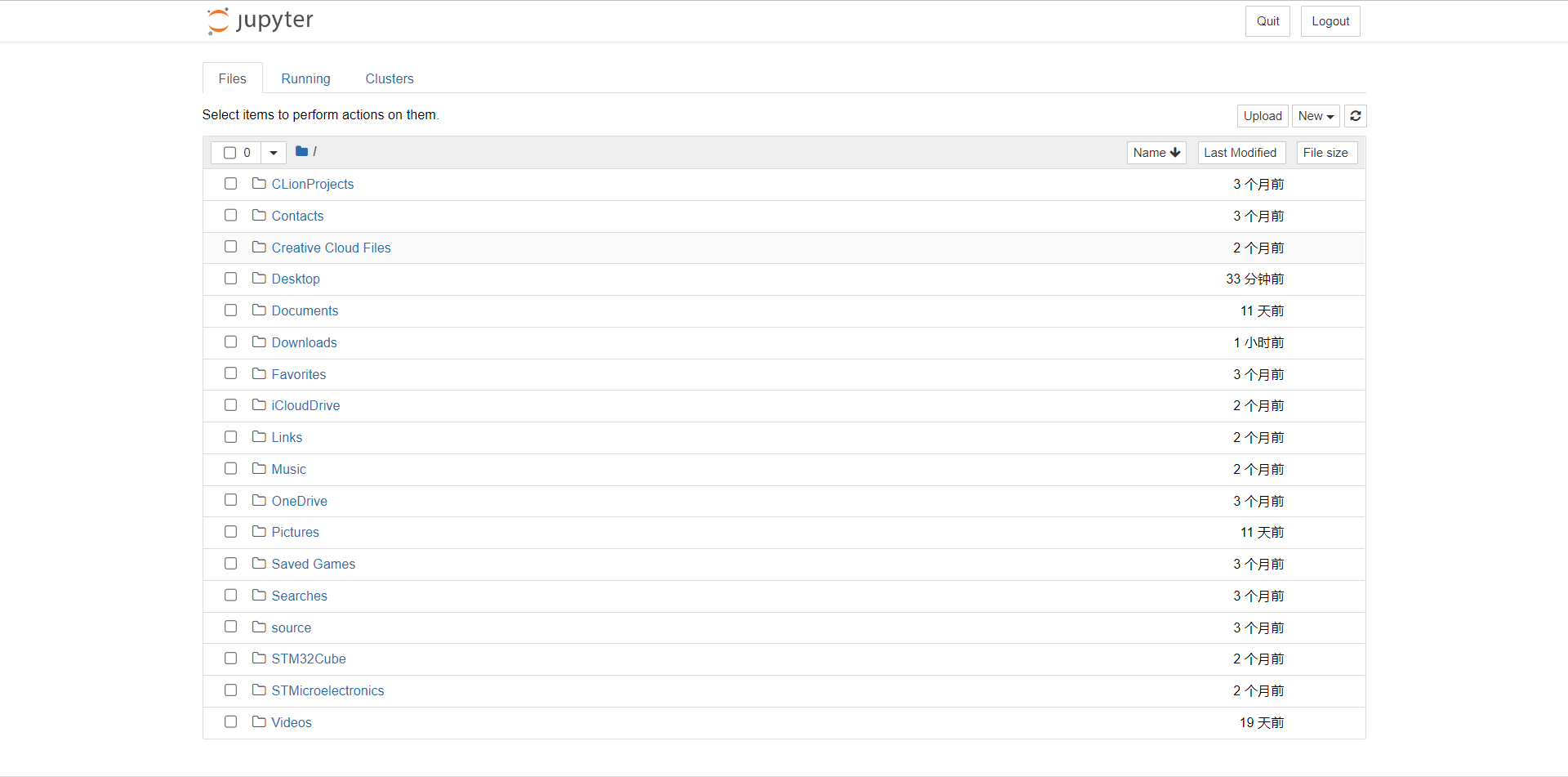
找到代码文件,双击打开
运行代码
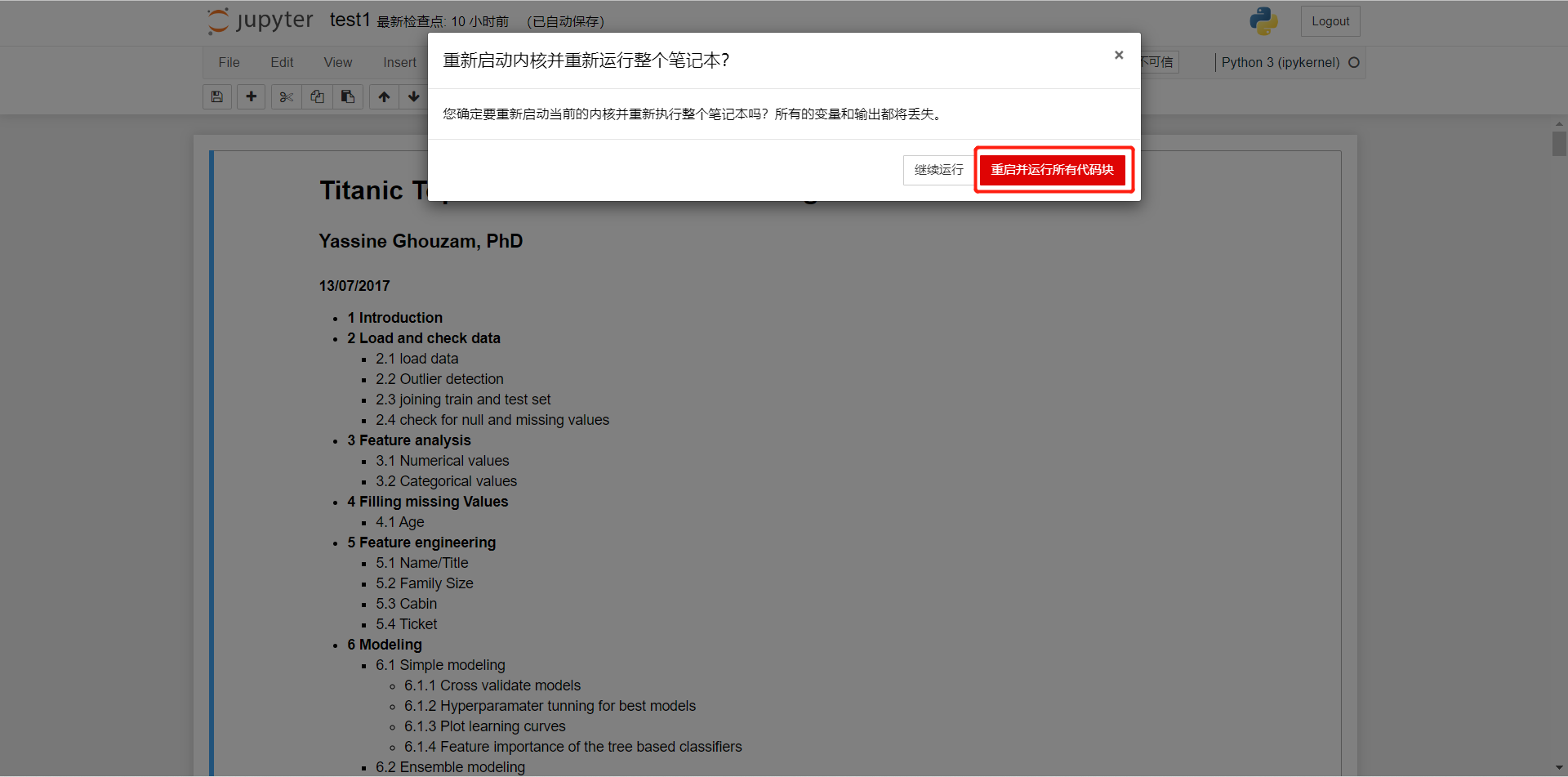
下载生成文件
使用Pycharm的同学可以在右上角选择在网页中打开,使用相同方法下载
温馨提示
- 如果无法运行,请着重的检查Python环境的问题
- 如果过程中遇到网络连接的问题,但访问其它的网站没问题的话,可以考虑科学上网
- 待补充
完结撒花~~
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 magic-H!
评论



